- 1. Introducción a DeepSeek
- 2. ¿Qué hace a DeepSeek una propuesta interesante?
- 3. ¿Por qué es relevante?
- 4. Enfoque Técnico de DeepSeek
- 5. Modelos Especializados
- 6. Un análisis de su impacto tecnológico, legal y económico
- 7. Bibliografía
- 8. Enlaces externos

1. Introducción a DeepSeek
IA | ¿Cómo aprende la Inteligencia Artificial de ‘Deepseek’? | EL PAÍS
DeepSeek es una familia de modelos extensos de lenguaje (LLM) desarrollada por High-Flyer (https://www.high-flyer.cn/en/), un fondo de inversión chino que ha decidido apostar por una solución de inteligencia artificial de alto rendimiento, abierta y escalable.
A diferencia de los grandes modelos comerciales y cerrados, DeepSeek ha sido diseñado con una serie de principios que lo hacen especialmente atractivo para quienes buscan independencia tecnológica, eficiencia y libertad de uso.
2. ¿Qué hace a DeepSeek una propuesta interesante?
- Eficiencia en costes y recursos: DeepSeek está optimizado para funcionar con un consumo contenido de memoria y potencia de cálculo, lo que lo hace ideal para entornos con recursos limitados.
- Alta capacidad de razonamiento: A pesar de su eficiencia, estos modelos ofrecen un nivel avanzado de comprensión y generación de texto, comparable al de soluciones mucho más costosas.
- Ejecución local: Una de sus principales ventajas es que puede ejecutarse en entornos locales (emplea Hugging Face para almacenar sus modelos), sin necesidad de depender de servicios en la nube ni de terceros, lo que mejora la privacidad y reduce la latencia.
- Licencia abierta (MIT): Su distribución bajo licencia MIT permite su uso libre incluso en contextos empresariales o institucionales con requisitos estrictos de auditoría y control (Ejemplo: DeepSeek-R1 License).
3. ¿Por qué es relevante?
DeepSeek representa una estrategia de democratización de la IA. Pone al alcance de:
- Empresas que necesitan control y seguridad sobre sus datos.
- Centros educativos que desean integrar IA en sus programas sin depender de grandes corporaciones.
- Desarrolladores y equipos técnicos que buscan soluciones personalizables y auditables.
Gracias a su enfoque abierto, DeepSeek permite crear proyectos de inteligencia artificial con transparencia, sostenibilidad y control total sobre la infraestructura y el uso.
4. Enfoque Técnico de DeepSeek
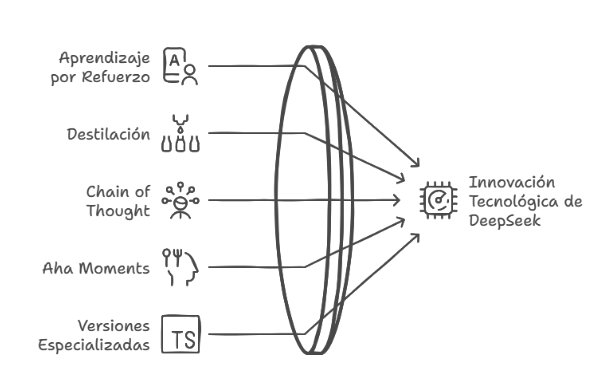
4.1. Técnicas Avanzadas de Entrenamiento
4.2. Aprendizaje por Refuerzo (RLHF)
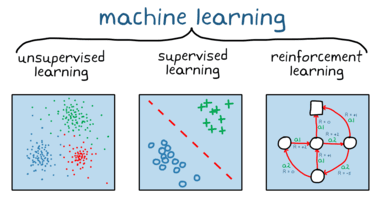
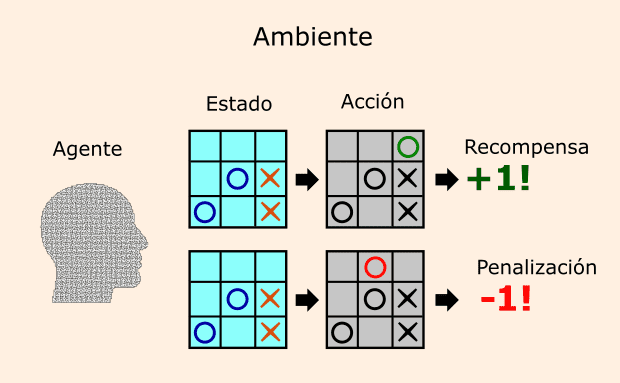
- ¿Cómo funciona?
- Entrena el modelo mediante retroalimentación humana y simulada, ajustando respuestas para alinearse con preferencias (ej.: claridad, ética).
- Ventaja: Reduce la dependencia de datos etiquetados y mejora el razonamiento contextual.
- Entrena el modelo mediante retroalimentación humana y simulada, ajustando respuestas para alinearse con preferencias (ej.: claridad, ética).
¿Qué es Reinforcement Learning o Aprendizaje por Refuerzo?
4.3. Destilación de Conocimiento: Simplificando Modelos de IA
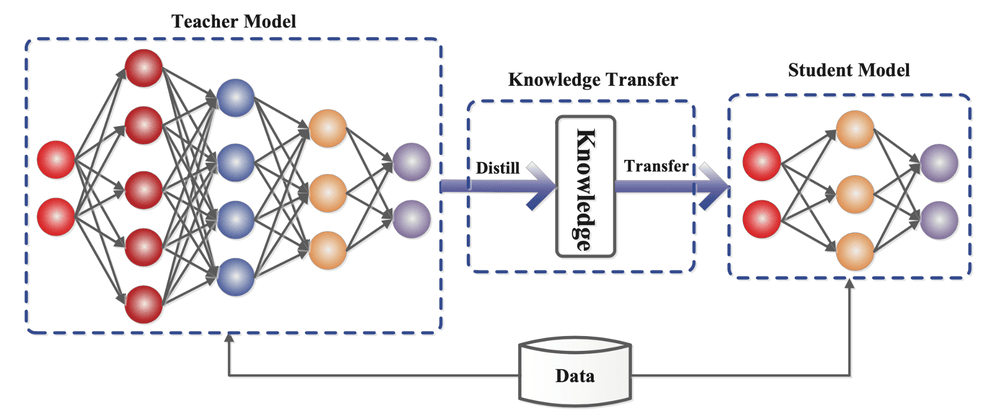
La destilación de conocimiento (o Knowledge Distillation) es una técnica que permite transferir las capacidades de un modelo de IA grande y complejo (llamado “teacher”) a otro modelo más pequeño y eficiente (“student”). El objetivo es mantener la mayor parte del rendimiento del modelo original, pero con menos recursos computacionales.
¿Cómo funciona?
- El modelo “teacher” (generalmente un modelo grande como DeepSeek-R1) genera predicciones o “conocimiento” en forma de probabilidades (ej.: clasificación de imágenes o generación de texto).
- El modelo “student” (una versión reducida) no solo aprende de los datos originales, sino también de las salidas suavizadas (soft labels) del modelo grande, que contienen información más rica que las etiquetas tradicionales (hard labels).
- Entrenamiento combinado: El modelo pequeño se optimiza para imitar tanto las respuestas del “teacher” como los datos reales, logrando un equilibrio entre precisión y eficiencia.
Ventajas de la Destilación
- Eficiencia: Modelos pequeños consumen menos memoria y energía, ideales para dispositivos móviles o entornos con recursos limitados.
- Costes reducidos: Menor necesidad de GPUs potentes para inferencia.
- Velocidad: Respuestas más rápidas en aplicaciones en tiempo real (ej.: asistentes de voz).
Imagina que el modelo DeepSeek-R1 (teacher) es un profesor experto, y DeepSeek-Coder-Lite (student) es un alumno avanzado. El profesor no solo le enseña respuestas correctas, sino también cómo razonar ante problemas ambiguos. Así, el alumno logra un rendimiento cercano al maestro, ¡pero con menos esfuerzo!
4.4. Chain-of-Thought (CoT)
Aplicación:
Divide problemas complejos en pasos intermedios, emulando el razonamiento humano. * Ejemplo:
Problema: "Si 3 manzanas cuestan $2, ¿cuánto cuestan 15?" CoT: "1. Coste por manzana = 2/3 ≈ $0.67. 2. Total = 15 × 0.67 ≈ $10".Beneficio: Mayor transparencia y precisión en tareas matemáticas/lógicas.
4.5. Aha! Moments (Autocorrección)
- Mecanismo:
- El modelo detecta inconsistencias en sus respuestas y las corrige on-the-fly.
- Caso de uso: En generación de código, identifica errores de sintaxis y propone alternativas.
- El modelo detecta inconsistencias en sus respuestas y las corrige on-the-fly.
5. Modelos Especializados
Además, se incluyen múltiples versiones especializadas: DeepSeek-R1, DeepSeek Coder, DeepSeek Math, DeepSeek VL (visión-lenguaje), adaptadas a tareas concretas.
6. Un análisis de su impacto tecnológico, legal y económico
6.1. Desafiando la Hegemonía de OpenAI y Anthropic
7.1. ¿Cómo compite DeepSeek con los gigantes de IA?*
Modelos abiertos vs. cerrados:
- OpenAI (GPT-4) y Anthropic (Claude) operan con modelos propietarios, mientras que DeepSeek usa licencia MIT (modificable y redistribuible).
- Ejemplo: Empresas pueden ajustar DeepSeek sin pagar licencias costosas.
- OpenAI (GPT-4) y Anthropic (Claude) operan con modelos propietarios, mientras que DeepSeek usa licencia MIT (modificable y redistribuible).
Eficiencia de costes:
- DeepSeek prioriza modelos más pequeños pero altamente optimizados (ej.: mediante destilación), reduciendo la necesidad de supercomputación.
- DeepSeek prioriza modelos más pequeños pero altamente optimizados (ej.: mediante destilación), reduciendo la necesidad de supercomputación.
Dato clave: DeepSeek-Coder compite con GitHub Copilot (de OpenAI/Microsoft) ofreciendo generación de código local sin dependencia de la nube.
6.2. Repercusiones Legales: La Batalla por los Datos
OpenAI alega que DeepSeek usó sus datasets (¿entrenó con datos de ChatGPT?) (The New York Times en Español “OpenAI dice que DeepSeek podría haber obtenido sus datos de manera indebida”).
6.3. Impacto en Bolsa
DeepSeek desarrolló su modelo con una inversión de solo 5,6 millones de dólares en hardware Nvidia, frente a los cientos de millones que gastan empresas como OpenAI. Esto genera dudas sobre: La rentabilidad del dominio de Nvidia en el mercado de GPUs para IA. La posibilidad de que empresas chinas compitan a menor coste y con alta eficiencia.
El 27 de enero de 2025, Nvidia sufrió una caída del 17% en sus acciones. Perdió aproximadamente 589.000 millones de dólares en capitalización bursátil. Esta caída representa la mayor pérdida en un solo día en la historia de Wall Street. Nvidia bajó en el ranking de empresas más valiosas del mundo, quedando detrás de Apple y Microsoft.
- Forbes España “La IA de DeepSeek provoca que Nvidia sufra la mayor pérdida bursátil de la historia: casi 600.000 millones”
- The Objective “Nvidia pierde más de 500.000 millones de dólares en bolsa por la irrupción de DeepSeek”
- EuroNews “La IA de DeepSeek sacude los mercados mundiales: Nvidia pierde 600.000 millones de dólares”
- JP Morgan “¿El drama de DeepSeek representa un punto de inflexión para el mercado de la inteligencia artificial (IA)?”
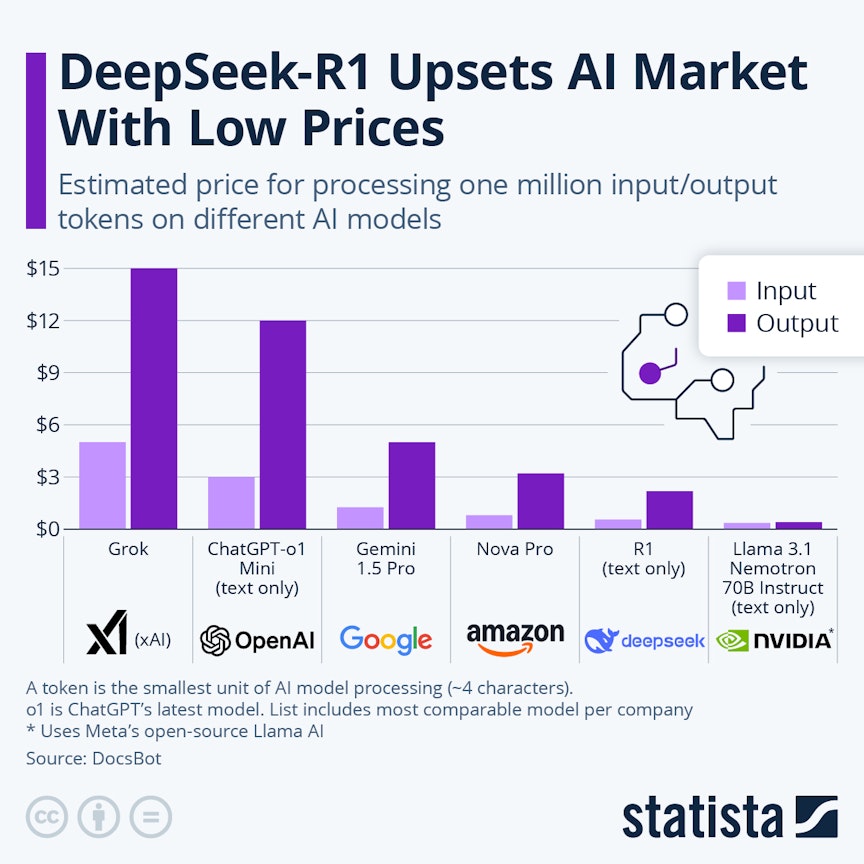
Statista “DeepSeek-R1 Upsets AI Market With Low Prices”
7. Bibliografía
Curso_DeepSeek.pdf. Autora: Leire Ahedo.
8. Enlaces externos
general
Destilación del conocimiento
🧠 Tutorial: Modelos de DeepSeek - Máster de Programación en IA
📌 Objetivo del Tutorial
Este tutorial tiene como objetivo presentar los principales modelos desarrollados por DeepSeek, una iniciativa de código abierto que está posicionándose como una alternativa poderosa a los modelos de lenguaje dominantes como GPT, LLaMA y Mistral. Analizaremos las características técnicas, casos de uso, fuentes y comparativas.
1. 🏢 ¿Qué es DeepSeek?
DeepSeek es una comunidad y laboratorio de investigación en IA con sede en China. Se ha enfocado en entrenar modelos de lenguaje (LLMs) con una arquitectura similar a GPT y compatibilidad con herramientas del ecosistema HuggingFace. Se caracteriza por ser open-source, eficiente en coste y competitivo en benchmarks.
🔗 Sitio oficial: https://deepseek.com
🔗 Repositorio en HuggingFace: https://huggingface.co/deepseek-ai
2. 📚 Clasificación de modelos DeepSeek
| Modelo | Tamaño | Tipo de modelo | Año | Características clave |
|---|---|---|---|---|
| DeepSeek-VL | ~7B | Multimodal (texto+imagen) | 2024 | Comprensión visual + texto, útil para VQA, OCR |
| DeepSeek-Coder | 1B–33B | Code LLM | 2024 | Entrenado para programación y razonamiento matemático |
| DeepSeek-MoE | 236B | Mixture-of-Experts | 2024 | Solo 12B activos por inferencia, eficiencia energética |
| DeepSeek-LLM | 7B/67B | LLM generalista | 2023–24 | Entrenamiento a gran escala en corpus web |
3. 🔍 Modelos destacados
🔹 DeepSeek-Coder
- 🧑💻 Orientado a programación
- Arquitectura: Decoder-only transformer
- Soporta múltiples lenguajes: Python, C++, JavaScript, etc.
- Preentrenamiento en código + fine-tuning con instrucciones (RLHF)
- Benchmarks competitivos: HumanEval, MBPP, Codeforces
Casos de uso:
- Generación de código asistida
- Compleción de código
- Explicación de fragmentos
- Resolución de problemas de programación
🔹 DeepSeek-VL (Vision-Language)
- 🖼️ Modelo Multimodal
- Entrada: Imagen + Texto
- Salida: Texto
- Usa imagen embebida con Vision Transformer
- Ideal para tareas de VQA (Visual Question Answering)
Casos de uso:
- OCR avanzado
- Asistencia a personas con baja visión
- Generación de subtítulos automáticos
- Análisis de diagramas técnicos
🔹 DeepSeek-MoE (Mixture-of-Experts)
- ⚙️ Modelo gigante pero eficiente
- 236B parámetros totales, solo 12.9B activos por paso
- Técnicas: Routing y sparsity en inferencia
- Gran relación coste-beneficio
Casos de uso:
- Chatbots de alto nivel
- Aplicaciones en edge computing
- Casos que requieren gran diversidad de tareas
4. 📈 Comparativa con otros modelos
| Modelo | Multimodal | Especialización en código | Arquitectura eficiente | Open Source |
|---|---|---|---|---|
| GPT-4 | Sí | Limitada | No | No |
| Mistral | No | No | Sí (MoE) | Sí |
| DeepSeek-Coder | No | Sí | Sí | Sí |
| DeepSeek-VL | Sí | Parcialmente | Sí | Sí |
| DeepSeek-MoE | No | No | Sí (sparse) | Sí |
5. 🧪 Actividades propuestas
Ejercicio 1: Explora DeepSeek-Coder
Utiliza el modelo deepseek-ai/deepseek-coder-6.7b-instruct en HuggingFace y haz que genere un programa en Python que resuelva una ecuación cuadrática. Luego, modifica el prompt para que comente cada línea.
Ejercicio 2: Comparativa con GPT-3.5
Proporciónale el mismo código a GPT-3.5 y DeepSeek-Coder. ¿Notas diferencias en claridad, eficiencia o comentarios?
Ejercicio 3: Evaluación Visual con DeepSeek-VL
Sube una imagen que contenga texto en varios idiomas y pide al modelo que lo transcriba. ¿Qué tal maneja el OCR?
6. 🧠 Preguntas de reflexión
- ¿Qué ventajas ofrece DeepSeek-MoE respecto a un modelo denso tradicional como GPT-3?
- ¿Qué diferencia clave existe entre DeepSeek-Coder y modelos como StarCoder o CodeLLaMA?
- ¿En qué escenarios prácticos usarías DeepSeek-VL frente a un modelo puramente textual?
- ¿Qué papel juega el fine-tuning en estos modelos y qué retos implica?
- ¿Cómo evalúas la ética de usar estos modelos en contextos educativos o médicos?
7. 📚 Fuentes de información
- Repositorio DeepSeek: https://huggingface.co/deepseek-ai
- Publicaciones DeepSeek: https://arxiv.org/search/?query=deepseek&searchtype=all
- Comparativas:
- Demo: https://deepseek.com
📬 Preguntas para ti, Iker:
- ¿Quieres que prepare ejemplos listos para ejecutarse en Google Colab con los modelos de HuggingFace?
- ¿Prefieres centrarte más en los modelos de código (DeepSeek-Coder) o quieres cubrir también los multimodales y los MoE?
- ¿Te interesaría incluir una sección práctica con evaluación de calidad de output (BLEU, CodeEval, etc.)?
- ¿El perfil de los alumnos incluye experiencia previa con Transformers y HuggingFace o necesitas incluir una introducción?
¿Te gustaría que este contenido lo convierta en una presentación de diapositivas o en Jupyter Notebook para una clase práctica?