- 1. Introducción a KNN
- 2. Concepto Básico
- 3. Métricas de Distancia
- 3.1. Distancia Euclidiana
- 4. Elección del Parámetro k
- 5. Ventajas y Limitaciones
- 5.1. Ventajas:
- 5.2. Limitaciones:
- 6. Aplicaciones Típicas
- 7. Conclusión
- 8. Referencias
- 9. Anexos
Tutorial: ¿Qué es K-Nearest Neighbors (KNN)?
K-vecinos | | UPV [07:57]
1. Introducción a KNN
El modelo K-Nearest Neighbors (KNN) es uno de los algoritmos más simples y efectivos para tareas de clasificación y regresión en aprendizaje automático. Es un método basado en instancias que no requiere suposiciones sobre la distribución de los datos y utiliza la proximidad entre puntos para realizar predicciones.

Ejemplo del algoritmo Knn. El ejemplo que se desea clasificar es el círculo verde. Para k = 3 este es clasificado con la clase triángulo, ya que hay solo un cuadrado y 2 triángulos, dentro del círculo que los contiene. Si k = 5 este es clasificado con la clase cuadrado, ya que hay 2 triángulos y 3 cuadrados, dentro del círculo externo.
2. Concepto Básico
KNN se basa en la idea de que objetos similares suelen estar cerca en el espacio de características. Para predecir el resultado de una nueva instancia, el modelo:
- Calcula las distancias entre la instancia y todos los puntos del conjunto de entrenamiento.
- Selecciona los k puntos más cercanos (los “vecinos más próximos”).
- Realiza una predicción basada en los valores de estos vecinos:
- Clasificación: Elige la clase más común entre los vecinos (votación por mayoría).
- Regresión: Calcula el promedio o valor ponderado de los vecinos.
3. Métricas de Distancia
KNN utiliza diferentes métricas para calcular la proximidad entre los puntos:
3.1. Distancia Euclidiana
Distancia Euclidiana: Esta es la medida de distancia más utilizada. Usando la siguiente fórmula, mide una línea recta entre el punto de consulta y el otro punto que se está midiendo (teorema de Pitágoras).
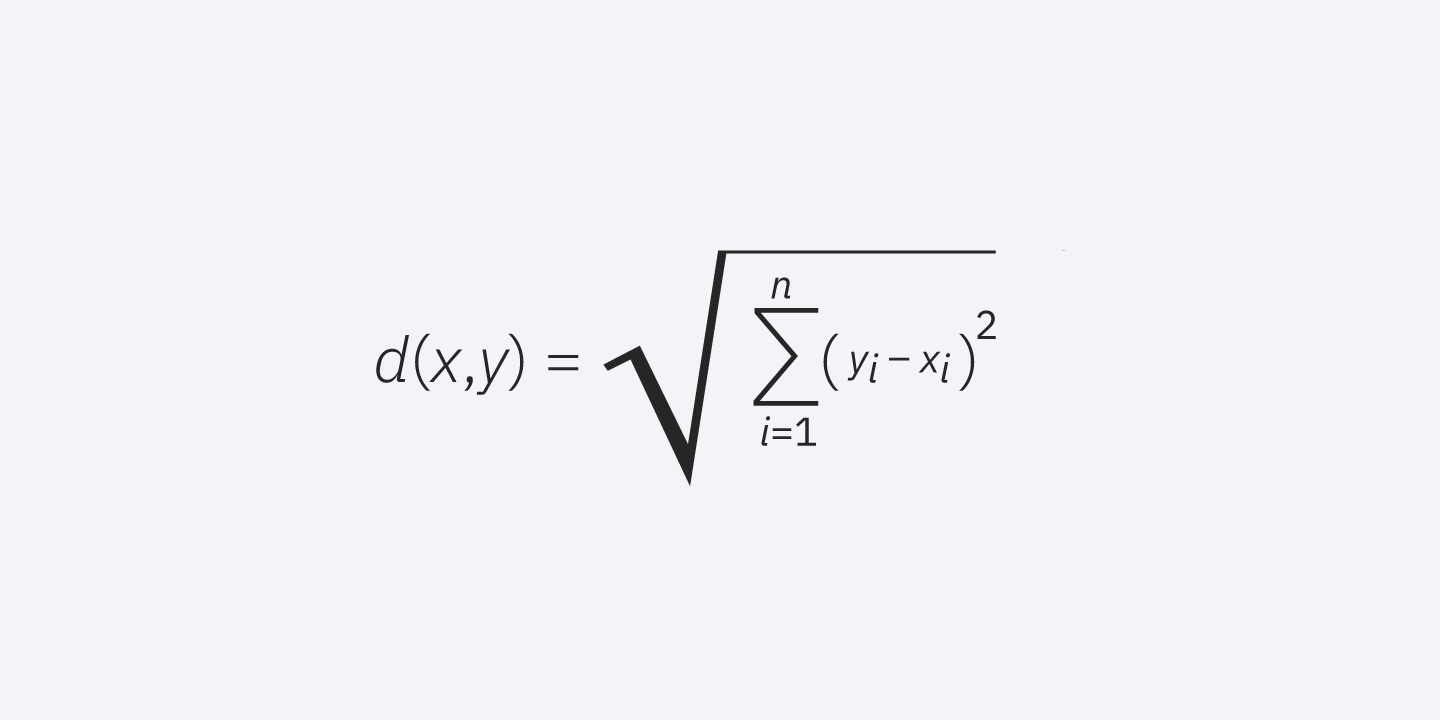
Puedes consultar al final de este artículo en anexos el Cálculo de la distancia euclidiana en Python
Distancia Manhattan: Esta es también otra métrica de distancia popular, que mide el valor absoluto entre dos puntos. También se la conoce como distancia en taxi (taxicab distance), ya que comúnmente se visualiza con una cuadrícula, que ilustra cómo uno puede navegar de una dirección a otra a través de las calles de la ciudad.


Distancia Manhattan contra distancia Euclidiana: Las líneas roja, azul y amarilla tienen la misma longitud (12) en las geometrías Euclidiana y taxicab. En la geometría Euclidiana, la línea verde tiene longitud 6×√2 ≈ 8.48, y es el único camino más corto. En la geometría taxicab, la línea verde tiene longitud 12, por lo que no es más corta que los otros caminos.
Manhattan distance vs. Euclidean distance.
Al final de este artículo en los anexos puedes ver como se calcula la distancia Manhattan en Python (Distancia de Manhattan en Python).
Distancia Minkowski (generalización de las anteriores):
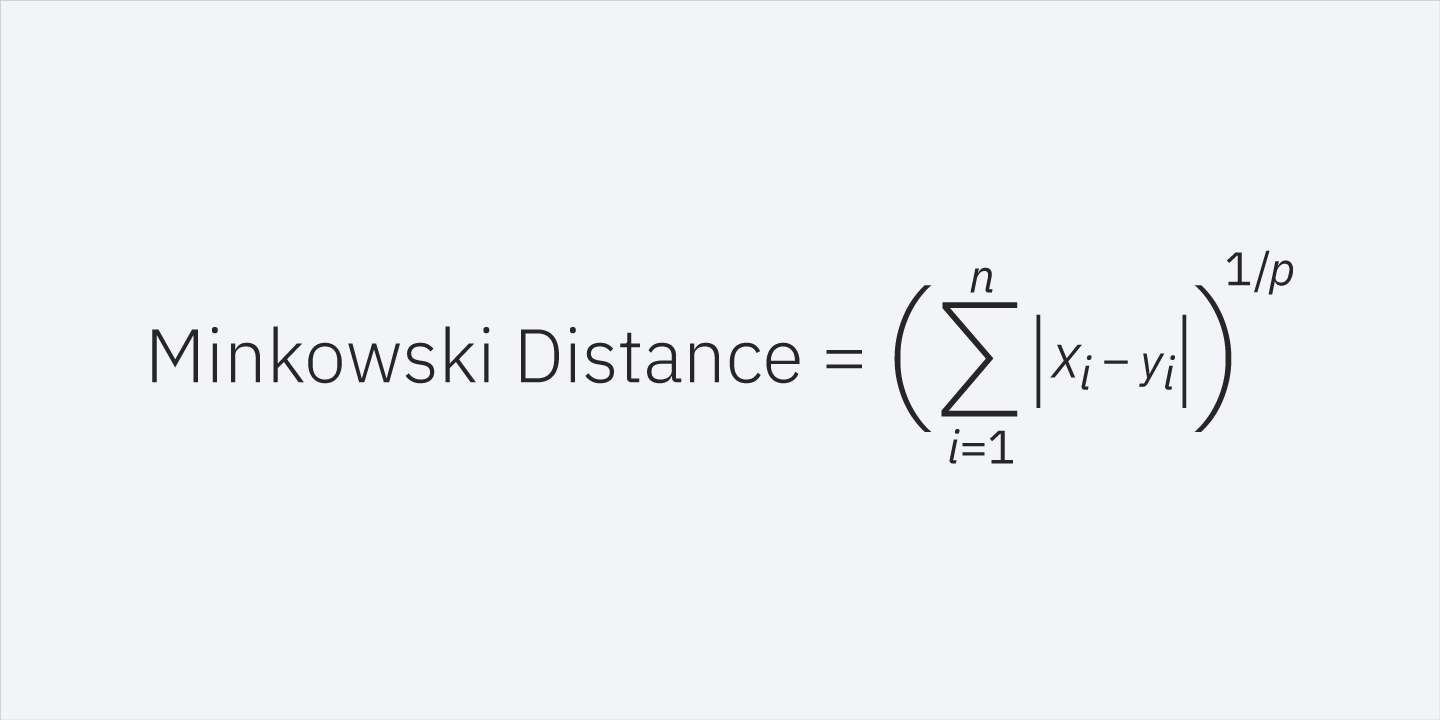
4. Elección del Parámetro k
El valor de k (número de vecinos) afecta directamente el rendimiento del modelo:
- Valores bajos de k pueden hacer que el modelo sea más sensible al ruido en los datos (sobreajuste).
- Valores altos de k suavizan las predicciones, pero pueden perder detalles importantes (subajuste).
La selección adecuada de k se realiza generalmente mediante validación cruzada.
5. Ventajas y Limitaciones
5.1. Ventajas:
- Simplicidad: Fácil de entender e implementar.
- Versatilidad: Funciona tanto para clasificación como para regresión.
- No paramétrico: No asume distribuciones específicas de los datos.
5.2. Limitaciones:
- Escalabilidad: La búsqueda de vecinos puede ser costosa para conjuntos de datos grandes.
- Sensibilidad: A la escala de las variables y a datos ruidosos.
6. Aplicaciones Típicas
- Reconocimiento de patrones: Clasificación de imágenes o señales.
- Sistemas de recomendación: Sugerir productos o contenidos basándose en preferencias similares.
- Análisis de datos biomédicos: Identificación de enfermedades o análisis genómico.
- Detección de intrusos: Clasificar accesos a sistemas como normales o anómalos.
7. Conclusión
KNN es un algoritmo intuitivo y poderoso que puede ser aplicado en una variedad de problemas. Sin embargo, su uso requiere un preprocesamiento cuidadoso de los datos y la elección adecuada del número de vecinos y la métrica de distancia para lograr un buen rendimiento.
8. Referencias
- https://www.datacamp.com/tutorial/euclidean-distance
- https://www.ibm.com/think/topics/knn
- https://www.datacamp.com/tutorial/manhattan-distance
- https://www.datacamp.com/tutorial/minkowski-distance
9. Anexos
9.1. Cálculo de la distancia euclidiana en Python
Código 03.py.
import numpy as np
from scipy.spatial.distance import euclidean
def euclidean_distance(point1, point2):
return np.sqrt(np.sum((np.array(point1) - np.array(point2))**2))
# 2D example
point_a = (1, 2)
point_b = (4, 6)
distance_2d = euclidean_distance(point_a, point_b)
print(f"2D Euclidean distance: {distance_2d:.2f}")
# 3D example
point_c = (1, 2, 3)
point_d = (4, 6, 8)
distance_3d = euclidean_distance(point_c, point_d)
print(f"3D Euclidean distance: {distance_3d:.2f}")
# Using SciPy for efficiency
distance_scipy = euclidean(point_c, point_d)
print(f"3D Euclidean distance (SciPy): {distance_scipy:.2f}")
Salida:
2D Euclidean distance: 5.00
3D Euclidean distance: 7.07
3D Euclidean distance (SciPy): 7.07
9.2. Distancia de Manhattan en Python
Cálculo utilizando matrices NumPy
Para un espacio tridimensional.
Código 01.py.
import numpy as np
point_a_np = np.array([1, 1, 1])
point_b_np = np.array([4, 5, 6])
distance_numpy = np.sum(np.abs(point_a_np - point_b_np))
print(f"Manhattan distance (NumPy): {distance_numpy}")
Salida:
Manhattan distance (NumPy): 12
Cálculo usando la función cityblock() de SciPy
Código 02.py.
from scipy.spatial.distance import cityblock
point_a = (1, 1, 1)
point_b = (4, 5, 6)
distance_scipy = cityblock(point_a, point_b)
print(f"Manhattan distance (SciPy): {distance_scipy}")
Salida:
Manhattan distance (SciPy): 12