{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Pandas Profiling: ejemplo de meteoritos de la NASA\n",
"\n",
"* Fuente original de los datos: [https://data.nasa.gov/Space-Science/Meteorite-Landings/gh4g-9sfh](https://data.nasa.gov/Space-Science/Meteorite-Landings/gh4g-9sfh)\n",
"* Ejemplo original del notebook [https://docs.profiling.ydata.ai/latest/getting-started/examples/](https://docs.profiling.ydata.ai/latest/getting-started/examples/)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
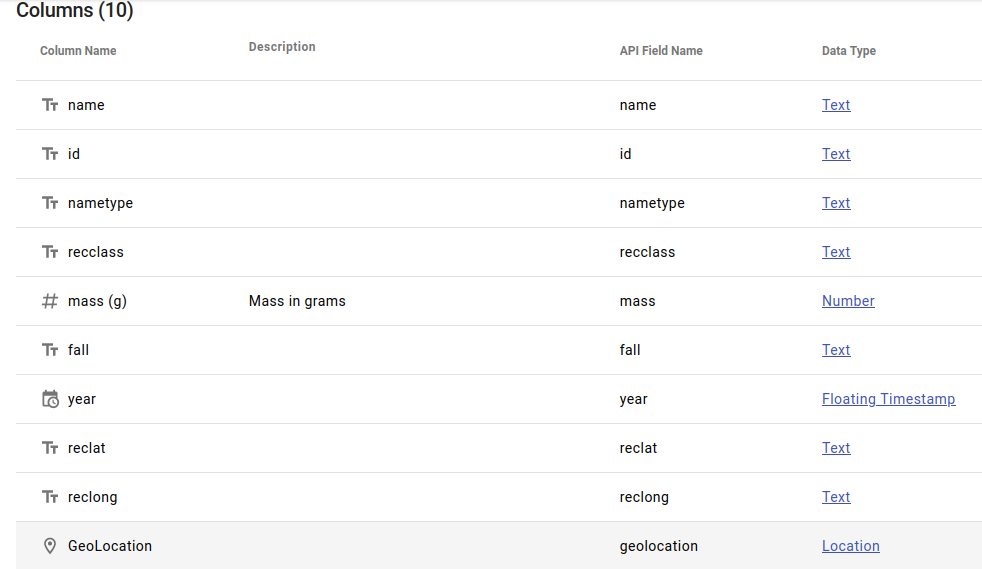
"El conjunto de datos Meteorite Landings de NASA contiene información detallada sobre meteoritos que han sido registrados en la Tierra. Los campos principales incluyen:\n",
"\n",
"* name: Nombre del meteorito.\n",
"* id: Identificador único para cada registro.\n",
"* nametype: Tipo de nombre (por ejemplo, \"Valid\" para meteoritos confirmados).\n",
"* recclass: Clasificación del meteorito según su composición.\n",
"* mass (g): Masa del meteorito en gramos.\n",
"* fall: Indica si el meteorito fue observado cayendo (\"Fell\") o fue encontrado posteriormente (\"Found\").\n",
"* year: Año en que el meteorito fue encontrado o cayó.\n",
"* reclat y reclong: Latitud y longitud de las coordenadas donde se registró el hallazgo.\n",
"* GeoLocation: Ubicación geográfica combinada en formato de texto."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Importar librerias"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"[ipywidgets](https://ipywidgets.readthedocs.io/en/stable/) es una librería de Python que facilita la creación de widgets interactivos en notebooks Jupyter"
]
},
{
"cell_type": "code",
"execution_count": 43,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Channels:\n",
" - defaults\n",
" - conda-forge\n",
"Platform: linux-64\n",
"Collecting package metadata (repodata.json): done\n",
"Solving environment: done\n",
"\n",
"## Package Plan ##\n",
"\n",
" environment location: /home/ir_inf/anaconda3/envs/pandas_profiling\n",
"\n",
" added / updated specs:\n",
" - ipywidgets\n",
"\n",
"\n",
"The following packages will be downloaded:\n",
"\n",
" package | build\n",
" ---------------------------|-----------------\n",
" ipywidgets-8.1.2 | py312h06a4308_0 244 KB\n",
" jupyterlab_widgets-3.0.10 | py312h06a4308_0 195 KB\n",
" widgetsnbextension-4.0.10 | py312h06a4308_0 947 KB\n",
" ------------------------------------------------------------\n",
" Total: 1.4 MB\n",
"\n",
"The following NEW packages will be INSTALLED:\n",
"\n",
" ipywidgets pkgs/main/linux-64::ipywidgets-8.1.2-py312h06a4308_0 \n",
" jupyterlab_widgets pkgs/main/linux-64::jupyterlab_widgets-3.0.10-py312h06a4308_0 \n",
" widgetsnbextension pkgs/main/linux-64::widgetsnbextension-4.0.10-py312h06a4308_0 \n",
"\n",
"\n",
"\n",
"Downloading and Extracting Packages:\n",
"widgetsnbextension-4 | 947 KB | | 0% \n",
"ipywidgets-8.1.2 | 244 KB | | 0% \u001b[A\n",
"\n",
"jupyterlab_widgets-3 | 195 KB | | 0% \u001b[A\u001b[A\n",
"ipywidgets-8.1.2 | 244 KB | ##4 | 7% \u001b[A\n",
"\n",
"widgetsnbextension-4 | 947 KB | #8 | 5% \u001b[A\u001b[A\n",
"\n",
"jupyterlab_widgets-3 | 195 KB | ##################################### | 100% \u001b[A\u001b[A\n",
"ipywidgets-8.1.2 | 244 KB | #############################1 | 79% \u001b[A\n",
" \u001b[A\n",
" \u001b[A\n",
"\n",
" \u001b[A\u001b[A\n",
"Preparing transaction: done\n",
"Verifying transaction: done\n",
"Executing transaction: done\n"
]
}
],
"source": [
"!conda install ipywidgets --yes"
]
},
{
"cell_type": "code",
"execution_count": 44,
"metadata": {},
"outputs": [],
"source": [
"from pathlib import Path\n",
"\n",
"import numpy as np\n",
"import pandas as pd\n",
"import requests\n",
"\n",
"import ydata_profiling\n",
"from ydata_profiling.utils.cache import cache_file\n",
"import ipywidgets"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"### Cargar y preparar un conjunto de datos de ejemplo"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Este código combina la descarga y carga de datos desde una URL."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"La función cache_file:\n",
"\n",
"* Descarga el archivo CSV desde la URL proporcionada.\n",
"* Lo guarda localmente con el nombre meteorites.csv (o verifica si ya existe en el caché para evitar descargarlo nuevamente).\n",
"* Retorna la ruta local al archivo, que se almacena en file_name."
]
},
{
"cell_type": "code",
"execution_count": 45,
"metadata": {},
"outputs": [
{
"data": {
"text/plain": [
"PosixPath('/home/ir_inf/anaconda3/envs/pandas_profiling/lib/python3.12/data/meteorites.csv')"
]
},
"execution_count": 45,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"file_name = cache_file(\n",
" \"meteorites.csv\",\n",
" \"https://data.nasa.gov/api/views/gh4g-9sfh/rows.csv?accessType=DOWNLOAD\",\n",
")\n",
"\n",
"file_name"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Leer el archivo en un DataFrame:"
]
},
{
"cell_type": "code",
"execution_count": 46,
"metadata": {},
"outputs": [
{
"data": {
"text/html": [
"\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" id | \n",
" nametype | \n",
" recclass | \n",
" mass (g) | \n",
" fall | \n",
" year | \n",
" reclat | \n",
" reclong | \n",
" GeoLocation | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Aachen | \n",
" 1 | \n",
" Valid | \n",
" L5 | \n",
" 21.0 | \n",
" Fell | \n",
" 1880.0 | \n",
" 50.77500 | \n",
" 6.08333 | \n",
" (50.775, 6.08333) | \n",
"
\n",
" \n",
" | 1 | \n",
" Aarhus | \n",
" 2 | \n",
" Valid | \n",
" H6 | \n",
" 720.0 | \n",
" Fell | \n",
" 1951.0 | \n",
" 56.18333 | \n",
" 10.23333 | \n",
" (56.18333, 10.23333) | \n",
"
\n",
" \n",
" | 2 | \n",
" Abee | \n",
" 6 | \n",
" Valid | \n",
" EH4 | \n",
" 107000.0 | \n",
" Fell | \n",
" 1952.0 | \n",
" 54.21667 | \n",
" -113.00000 | \n",
" (54.21667, -113.0) | \n",
"
\n",
" \n",
" | 3 | \n",
" Acapulco | \n",
" 10 | \n",
" Valid | \n",
" Acapulcoite | \n",
" 1914.0 | \n",
" Fell | \n",
" 1976.0 | \n",
" 16.88333 | \n",
" -99.90000 | \n",
" (16.88333, -99.9) | \n",
"
\n",
" \n",
" | 4 | \n",
" Achiras | \n",
" 370 | \n",
" Valid | \n",
" L6 | \n",
" 780.0 | \n",
" Fell | \n",
" 1902.0 | \n",
" -33.16667 | \n",
" -64.95000 | \n",
" (-33.16667, -64.95) | \n",
"
\n",
" \n",
" | ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
" ... | \n",
"
\n",
" \n",
" | 45711 | \n",
" Zillah 002 | \n",
" 31356 | \n",
" Valid | \n",
" Eucrite | \n",
" 172.0 | \n",
" Found | \n",
" 1990.0 | \n",
" 29.03700 | \n",
" 17.01850 | \n",
" (29.037, 17.0185) | \n",
"
\n",
" \n",
" | 45712 | \n",
" Zinder | \n",
" 30409 | \n",
" Valid | \n",
" Pallasite, ungrouped | \n",
" 46.0 | \n",
" Found | \n",
" 1999.0 | \n",
" 13.78333 | \n",
" 8.96667 | \n",
" (13.78333, 8.96667) | \n",
"
\n",
" \n",
" | 45713 | \n",
" Zlin | \n",
" 30410 | \n",
" Valid | \n",
" H4 | \n",
" 3.3 | \n",
" Found | \n",
" 1939.0 | \n",
" 49.25000 | \n",
" 17.66667 | \n",
" (49.25, 17.66667) | \n",
"
\n",
" \n",
" | 45714 | \n",
" Zubkovsky | \n",
" 31357 | \n",
" Valid | \n",
" L6 | \n",
" 2167.0 | \n",
" Found | \n",
" 2003.0 | \n",
" 49.78917 | \n",
" 41.50460 | \n",
" (49.78917, 41.5046) | \n",
"
\n",
" \n",
" | 45715 | \n",
" Zulu Queen | \n",
" 30414 | \n",
" Valid | \n",
" L3.7 | \n",
" 200.0 | \n",
" Found | \n",
" 1976.0 | \n",
" 33.98333 | \n",
" -115.68333 | \n",
" (33.98333, -115.68333) | \n",
"
\n",
" \n",
"
\n",
"
45716 rows × 10 columns
\n",
"
\n",
"\n",
"
\n",
" \n",
" \n",
" | \n",
" name | \n",
" id | \n",
" nametype | \n",
" recclass | \n",
" mass (g) | \n",
" fall | \n",
" year | \n",
" reclat | \n",
" reclong | \n",
" GeoLocation | \n",
" source | \n",
" boolean | \n",
" mixed | \n",
" reclat_city | \n",
"
\n",
" \n",
" \n",
" \n",
" | 0 | \n",
" Aachen | \n",
" 1 | \n",
" Valid | \n",
" L5 | \n",
" 21.0 | \n",
" Fell | \n",
" 1880-01-01 | \n",
" 50.77500 | \n",
" 6.08333 | \n",
" (50.775, 6.08333) | \n",
" NASA | \n",
" False | \n",
" A | \n",
" 47.245529 | \n",
"
\n",
" \n",
" | 1 | \n",
" Aarhus | \n",
" 2 | \n",
" Valid | \n",
" H6 | \n",
" 720.0 | \n",
" Fell | \n",
" 1951-01-01 | \n",
" 56.18333 | \n",
" 10.23333 | \n",
" (56.18333, 10.23333) | \n",
" NASA | \n",
" True | \n",
" A | \n",
" 49.824794 | \n",
"
\n",
" \n",
" | 2 | \n",
" Abee | \n",
" 6 | \n",
" Valid | \n",
" EH4 | \n",
" 107000.0 | \n",
" Fell | \n",
" 1952-01-01 | \n",
" 54.21667 | \n",
" -113.00000 | \n",
" (54.21667, -113.0) | \n",
" NASA | \n",
" True | \n",
" 1 | \n",
" 52.399247 | \n",
"
\n",
" \n",
"
\n",
"