- 1. Matriz de confusión
- 2. Estructura de la matriz de confusión
- 3. Ejemplo de interpretación
- 4. Métricas derivadas de la matriz de confusión
- 4.1. Precisión (Accuracy)
- 4.2. Exactitud (Accuracy)
- 4.3. Recordatorio (Recall)
- 4.4. Valor-F (F-measure o F1-score)
- 5. Referencias
1. Matriz de confusión
MATRIZ DE CONFUSIÓN | #32 Curso Machine Learning con Python (3:49)
Una matriz de confusión te ayuda a evaluar el rendimiento de un modelo de clasificación (aprendizaje supervisado.) comparando las predicciones hechas por el modelo con las etiquetas reales. En el caso del dataset Iris, que tiene tres clases de flores (setosa, versicolor, y virginica), la matriz de confusión será una matriz de 3x3 (siendo las dimensiones iguales al número de clases).
Cada columna de la matriz representa el número de predicciones de cada clase, mientras que cada fila representa a las instancias en la clase real. Uno de los beneficios de las matrices de confusión es que facilitan ver si el sistema está confundiendo dos clases.
2. Estructura de la matriz de confusión
Para un modelo de clasificación de 3 clases, la matriz de confusión generalmente tiene esta estructura:

Cada celda se interpreta así:
- TP (True Positives): Los valores en la diagonal representan las predicciones correctas. Por ejemplo, el valor en la celda superior izquierda (
TP_{setosa}) indica cuántas veces el modelo predijo correctamente la clasesetosa. - FP (False Positives): Los valores fuera de la diagonal representan los errores. Por ejemplo, el valor en la celda
(1,2)indica el número de veces que el modelo predijoversicolorcuando la clase real erasetosa.
3. Ejemplo de interpretación
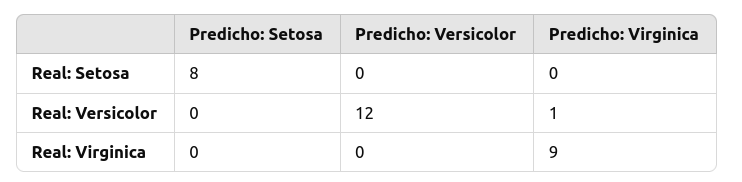
Supón que la matriz de confusión para el conjunto de datos Iris es:
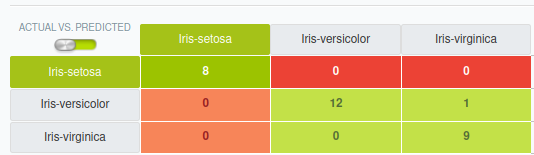
Esto significa:
setosa: El modelo predijo correctamente las 8 instancias desetosa.versicolor: El modelo predijo correctamente 12 instancias deversicolor, pero clasificó incorrectamente 1 de ellas comovirginica.virginica: El modelo predijo correctamente 9 instancias devirginica.
4. Métricas derivadas de la matriz de confusión
EVALUANDO EL ERROR EN LOS MODELOS DE CLASIFICACIÓN | #33 Curso Machine Learning con Python (5:48)
4.1. Precisión (Accuracy)
La Precisión (Precision) Es el porcentaje de predicciones correctas (True Positives o TP ), dada por:
Precision = TP / (TP + FP)
o lo que es lo mismo:
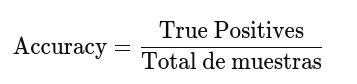
Cuanto mayor sea este número, más posibilidades tendrá de identificar correctamente todos los positivos. Si se trata de una puntuación baja, habrá predicho muchos positivos donde no los había.
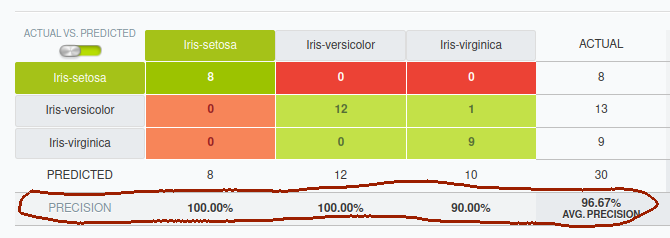
Ejemplo: Cálculo de Precisión para Iris-virginica
- Verdaderos Positivos (TP) para Iris-virginica: Las veces que el modelo predijo correctamente Iris-virginica, que es el valor en la celda (2,2) = 9.
- Falsos Positivos (FP) para Iris-virginica: Las veces que el modelo predijo Iris-virginica incorrectamente cuando la clase real era otra. En este caso, solo hay una predicción incorrecta de Iris-virginica cuando la clase real era Iris-versicolor (celda (1,2) = 1).
Entonces, la precisión para Iris-virginica se calcula como:
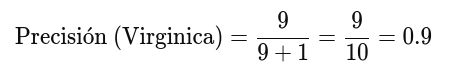
La precisión para Iris-virginica es 0.9 o 90%, lo que significa que el modelo fue correcto el 90% de las veces que predijo Iris-virginica.
4.2. Exactitud (Accuracy)
Exactitud (Accuracy): es la cantidad de predicciones correctas sobre la cantidad total de instancias que se han evaluado. Esto es, la exactitud es la proporción de resultados verdaderos (tanto verdaderos positivos (TP) como verdaderos negativos (TN)) entre el número total de casos examinados (verdaderos positivos, falsos positivos, verdaderos negativos, falsos negativos).
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Ejemplo
Para calcular la exactitud o accuracy de la clasificación en este caso, necesitamos dividir el número total de predicciones correctas entre el número total de predicciones realizadas.
- Predicciones correctas (suma de la diagonal):
- Setosa: 8
- Versicolor: 12
- Virginica: 9
- Total de predicciones correctas = 8+12+9=298+12+9=29.
- Total de predicciones realizadas: Esto incluye todas las celdas de la matriz de confusión.
Total de muestras = 8+0+0+0+12+1+0+0+9=308+0+0+0+12+1+0+0+9=30.
La exactitud se calcula como:

La exactitud es 0.9667 o 96.67%, lo que significa que el modelo clasifica correctamente el 96.67% de las instancias en este conjunto de datos.
4.3. Recordatorio (Recall)
El recall (o sensibilidad, o tasa de verdaderos positivos) es una métrica que mide la capacidad del modelo para identificar correctamente todas las instancias positivas de una clase específica. En otras palabras, el recall responde a la pregunta: “¿De todos los ejemplos de una clase, cuántos identificó correctamente el modelo?”
Fórmula del Recall
El recall para una clase específica se define como:

Cálculo del Recall para Iris-versicolor
- Verdaderos Positivos (TP): Las instancias en las que la clase real y la predicha fueron ambas Iris-versicolor, que se encuentran en la celda (1,1) = 12.
- Falsos Negativos (FN): Las instancias en las que la clase real era Iris-versicolor, pero el modelo predijo una clase diferente. En este caso, hay un falso negativo en la celda (1,2) = 1, donde el modelo clasificó una instancia de Iris-versicolor como Iris-virginica.
Entonces, el recall para Iris-versicolor se calcula como:
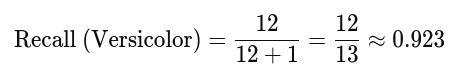
El recall para Iris-versicolor es aproximadamente 0.923 o 92.3%, lo que significa que el modelo identificó correctamente el 92.3% de las instancias de Iris-versicolor en el conjunto de datos, pero dejó de identificar el 7.7% (es decir, clasificó una instancia real de Iris-versicolor como Iris-virginica).
4.4. Valor-F (F-measure o F1-score)
La F-measure o F1-score es una métrica que combina la precisión y el recall en un único valor para evaluar el rendimiento del modelo, especialmente útil cuando tenemos un desbalance entre estos dos valores. La F1-score busca el equilibrio entre la precisión y el recall, dándonos una idea de qué tan bien el modelo identifica correctamente una clase sin ignorar las instancias de esa clase.
La F1-score se define como la media armónica de la precisión y el recall:
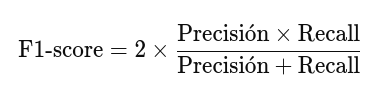
Ejemplo: Cálculo de F1-Score para Iris-versicolor
Supongamos que ya hemos calculado estos valores para la clase Iris-versicolor:
- Precisión: 1.0 (100%)
- Recall: 0.923 (92.3%)
Sustituyendo estos valores en la fórmula de F1-score:
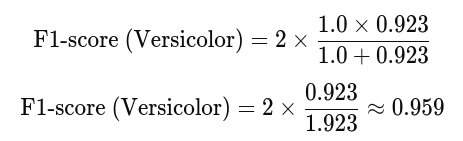
El F1-score para Iris-versicolor es aproximadamente 0.959 o 95.9%. Este valor sugiere que el modelo tiene un buen equilibrio entre precisión y recall para identificar correctamente las instancias de Iris-versicolor.
La F1-score es particularmente útil en casos de clasificación desbalanceada o cuando es crucial equilibrar entre no perder instancias de una clase (alto recall) y ser preciso al identificarlas (alta precisión).
5. Referencias
- https://machinelearningmastery.com/bigml-tutorial-develop-your-first-decision-tree-and-make-predictions/
- https://static.bigml.com/static/html-doc/Classification_and_Regression/sect0001.html
- https://static.bigml.com/static/html-doc/Classification_and_Regression/cha-models.html
- https://support.bigml.com/hc/en-us/articles/207539549-How-can-I-interpret-the-evaluation-results-for-my-classification-model
- https://www.juanbarrios.com/la-matriz-de-confusion-y-sus-metricas/