- 1. Problema de clasificación de especies de iris
- 2. Cargar datos y crear un conjunto de datos
- 3. Crear y evaluar el modelo
- 4. Referencias
1. Problema de clasificación de especies de iris
Para este tutorial, utilizaremos el conjunto de datos de flores de iris, que ha sido ampliamente estudiado. Este conjunto de datos está compuesto por 150 instancias que describen las medidas de las flores de iris, cada una de las cuales se clasifica como una de las tres especies de iris. Los atributos son numéricos y el problema es un problema de clasificación de múltiples clases.
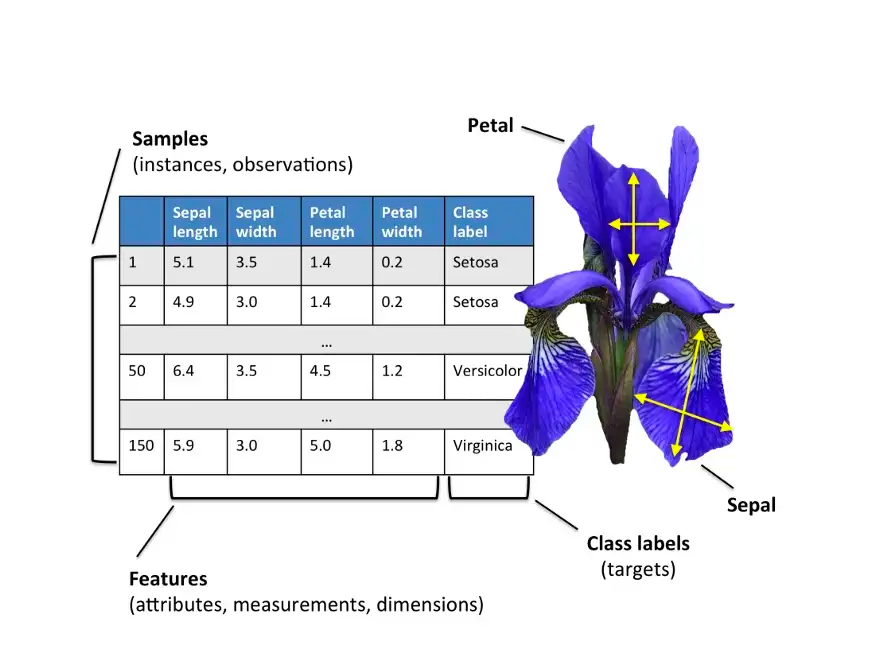
Puede leer más sobre este problema en la página de Wikipedia y descargar los datos de la página de Iris en el Repositorio de aprendizaje automático de la UCI (en local iris.zip).
2. Cargar datos y crear un conjunto de datos
En esta sección, preparará su fuente de datos y su conjunto de datos para utilizarlos en BigML.
2.1. Crear la fuente de datos
Puedes usar la URL para cargar los datos: http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data.
Notarás que los tipos de datos de atributos se han identificado correctamente como numéricos y que la etiqueta de clase es el último atributo (field5).
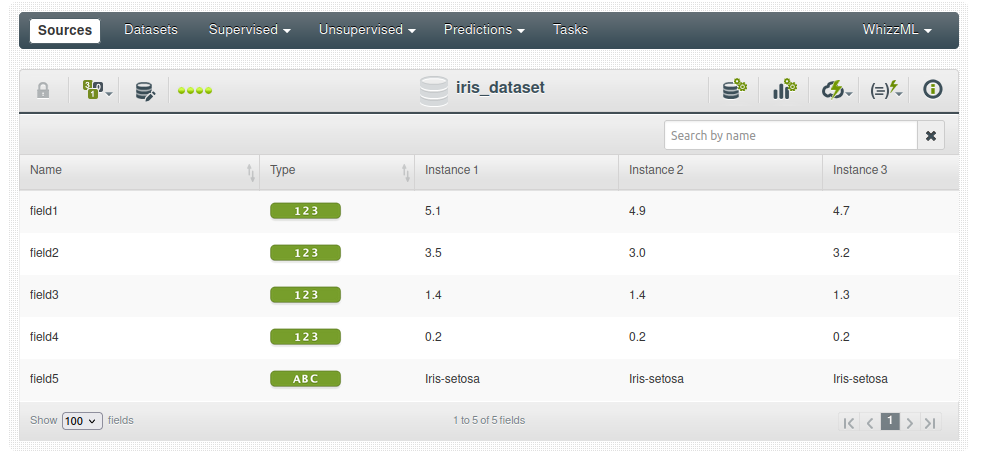
2.2. Crear el conjunto de datos
Ahora divide en dos subconjuntos de test y entrenamiento en 1 click:
3. Crear y evaluar el modelo
3.1. Crear modelo predictivo
Ahora creará un modelo predictivo a partir del conjunto de datos de entrenamiento.
Pase el cursor sobre diferentes nodos del modelo para revisar el flujo de datos a través del árbol de decisiones.
Haga clic en el botón “Sunburst” para abrir la vista Sunburst del modelo y explorar el árbol de decisiones.
3.1.1. Informe de resumen del modelo
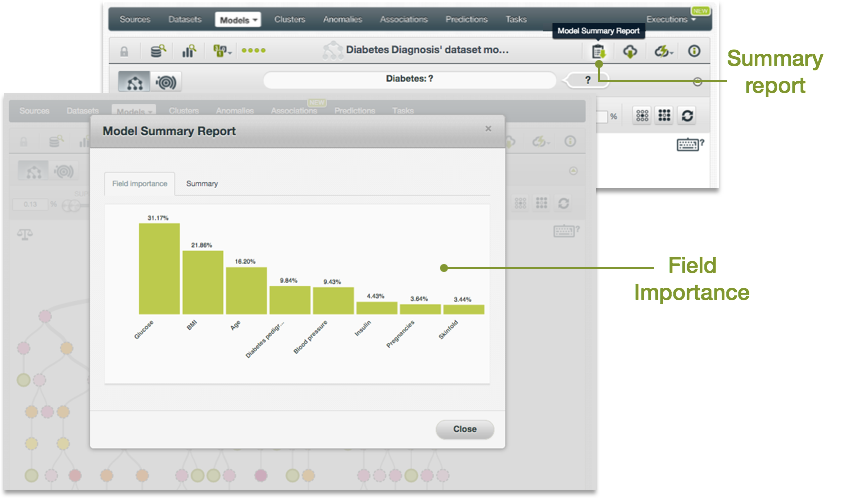
Haga clic en el botón “Informe de resumen del modelo” para revisar una descripción de texto de las reglas derivadas del modelo de árbol de decisiones.
Desde la vista de detalle de un modelo, puede acceder al informe de resumen del modelo haciendo clic en el ícono resaltado en la figura:

El informe de resumen del modelo tiene dos pestañas: importancia del campo y resumen, que se explican en las siguientes subsecciones.
Importancia del campo
La importancia del campo le proporciona una medida de la importancia de un campo en relación con los demás campos (Ver 1.2.5 Field importance para obtener más detalles).
La importancia del campo es la contribución relativa de cada campo a las predicciones del campo objetivo. Por lo tanto, un campo con mayor importancia tendrá un mayor impacto en las predicciones. Puede encontrar un histograma visual que contiene la importancia de todos los campos en el Informe de resumen del modelo.
Los campos con una importancia de cero aún pueden estar correlacionados con el campo objetivo. Simplemente significa que el modelo prefirió otros campos al elegir divisiones.
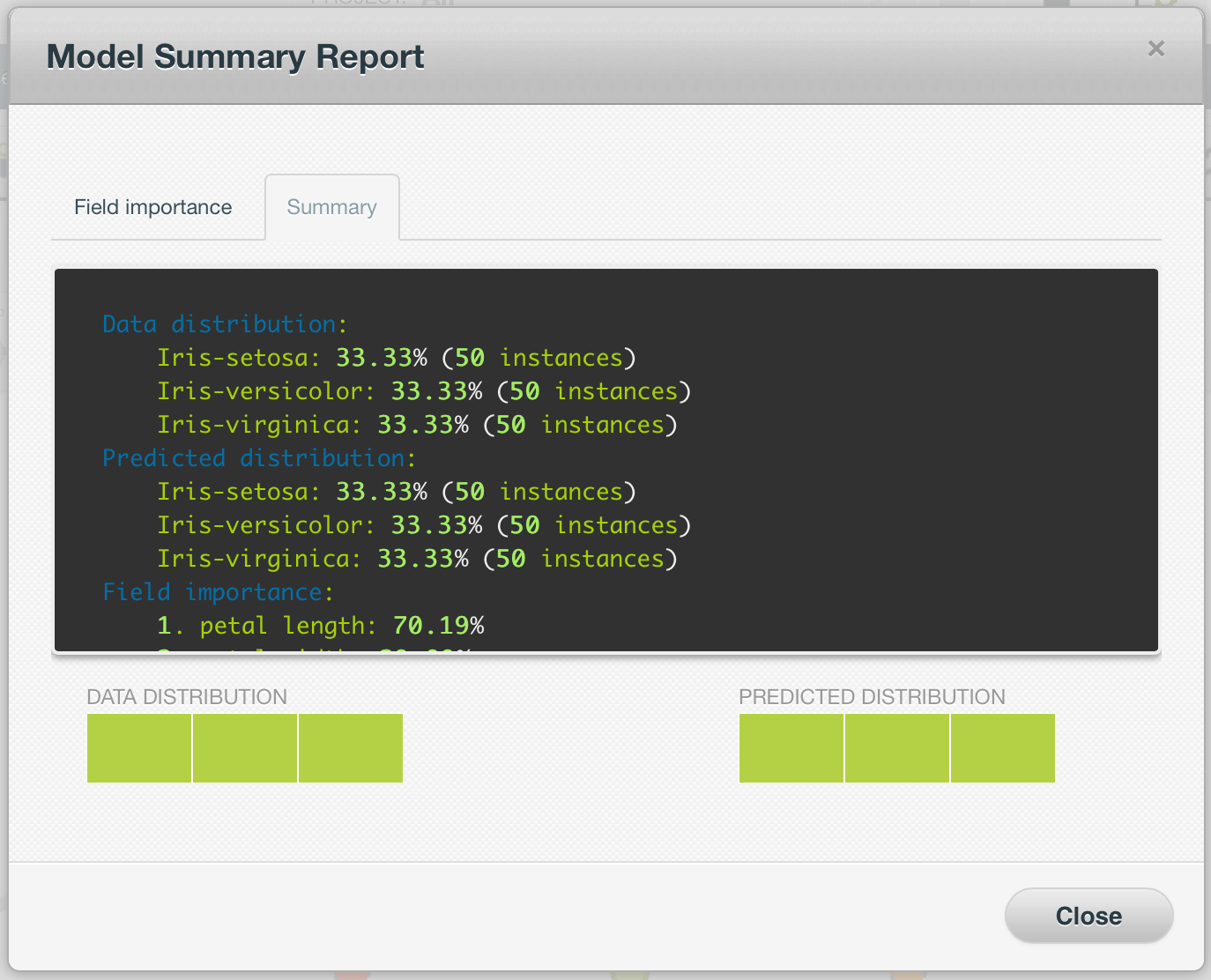
Resumen
Esta vista resumida de su modelo incluye:
- Distribución de datos: para problemas de clasificación, porcentaje de las instancias del conjunto de datos que pertenecen a cada una de las clases de campos objetivos; para regresiones, esta es la distribución de campos objetivos.
- Distribución predicha: para problemas de clasificación, porcentaje de instancias predichas para cada una de las clases de campos objetivos; para regresiones.
- Importancia de campo: una medida de cuán importante es un campo en relación con los otros campos (vea también la subsección 1.2.5).
- Resumen de reglas: un resumen de las reglas que el modelo aprendió del conjunto de datos. Esto significa que para cada posible resultado de predicción, puede encontrar aquí un resumen de las rutas que producirían esa predicción.
3.2. Evaluar modelo predictivo
- Haga clic en el modelo de flor de iris en la pestaña “Modelos”.
- Haga clic en el botón de la nube y seleccione “Evaluar”.
- La evaluación seleccionará automáticamente el conjunto de datos de prueba que creó anteriormente y que contiene el 20 % del conjunto de datos original que el modelo predictivo no ha visto antes.
La precisión del modelo se resume en términos de precisión de clasificación, precisión, recuperación, puntuación F y puntuación phi. Podemos ver que la precisión es del 93,33 %.
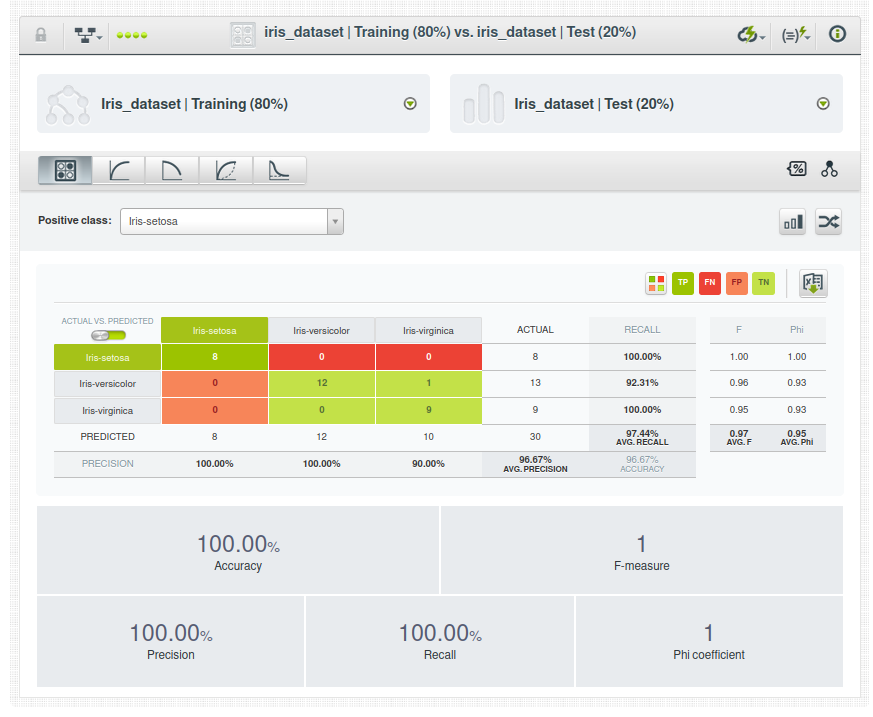
En el caso de los modelos de clasificación, los resultados de la evaluación se basan en las siguientes métricas o medidas:
- Exactitud (Accuracy): es la cantidad de predicciones correctas sobre la cantidad total de instancias que se han evaluado.
- Precisión (Precision): cuanto mayor sea este número, más posibilidades tendrá de identificar correctamente todos los positivos. Si se trata de una puntuación baja, habrá predicho muchos positivos donde no los había.
- Recordatorio: si esta puntuación es alta, no habrá pasado por alto muchos positivos. Pero, a medida que se reduce, no estará prediciendo los positivos que realmente existen.
- Valor-F(F-measure o F1-score) : es la media armónica equilibrada de Recordatorio y Precisión, lo que otorga a ambas métricas el mismo peso. Cuanto mayor sea la medida F, mejor.
- Coeficiente Phi: el coeficiente Phi tiene en cuenta los negativos verdaderos (explícitamente). Cuál es el adecuado depende de cuánta atención desee prestar a todos esos ejemplos negativos que está acertando. Si estos son muy importantes para usted (como puede ser el caso en el diagnóstico médico), Phi puede ser mejor. Si no son muy importantes (como al intentar devolver resultados de búsqueda relevantes), F-Measure suele ser más adecuado.
4. Referencias
- https://machinelearningmastery.com/bigml-tutorial-develop-your-first-decision-tree-and-make-predictions/
- https://static.bigml.com/static/html-doc/Classification_and_Regression/sect0001.html
- https://static.bigml.com/static/html-doc/Classification_and_Regression/cha-models.html
- https://support.bigml.com/hc/en-us/articles/207539549-How-can-I-interpret-the-evaluation-results-for-my-classification-model
- https://www.juanbarrios.com/la-matriz-de-confusion-y-sus-metricas/