- 1. Métodos de regresión
- 1.1. Regresión lineal
1. Métodos de regresión
1.1. Regresión lineal
El modelo más conocido es la regresión lineal, donde se busca predecir un valor Y = f (X) a partir de unos datos de entrada X y asumiendo que la distribución de los datos es lineal, es decir:
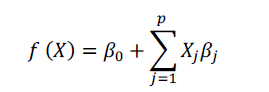
donde los valores Xjβj pueden ser, bien representaciones lineales, bien polinómicas.
Las regresiones lineales pueden ser simples o condicionadas. En el segundo caso tendríamos un parámetro de regularización que dividiría el tipo de modelo en tres: Ridge regression, LASSO regression y Elastic Net regression.
- Ridge regression. En este modelo los coeficientes de regresión son “contraídos” y se impone una penalización (penalty) a su tamaño. Más particularmente, los coeficientes minimizan una suma residual de cuadrados penalizados. Al usar este método, se resuelve el problema producido por la presencia de variables Xj correlacionadas en los datos y, debido a eso, los coeficientes βj a los que van multiplicados resultan poco determinados y exhiben una alta varianza.
- LASSO (Least Absolute Shrinkage and Selection Operator) regression. Este modelo es similar al anterior, pero en este caso la penalización a la que se someten los coeficientes es lineal y no cuadrática. Esto hace que las soluciones de la variable o variables de salida sean no lineales.
- Elastic Net regression. Este modelo combina las penalizaciones propias de las regresiones LASSO y Ridge de tal forma que se intenten evitar las limitaciones de cada uno de los dos modelos.
1.1.1. Ejercicio
En este ejercicio se busca utilizar el entorno Orange para predecir el valor de una variable asumiendo que el modelo tiene un comportamiento lineal. Como el valor es numérico, se definirá y estudiará un modelo de regresión lineal.
En primer lugar, se procede a abrir el entorno de Orange y se guarda el archivo con el nombre Ejemplo_Regresión_Lineal. El fichero se guardará con la extensión .ows en el directorio que decida el usuario. Para realizar una regresión lineal sobre unos datos basta con hacer uso de tres widgets: un archivo de datos, un modelo de regresión lineal y un widget para comprobar los resultados.
En primer lugar, arrastramos al canvas un widget File de la sección Data, después un modelo de regresión lineal en la sección Model y, por último, un widget Test and Score ubicado en la sección Evaluate. Creamos el flujo de trabajo tal y como se muestra en la figura:
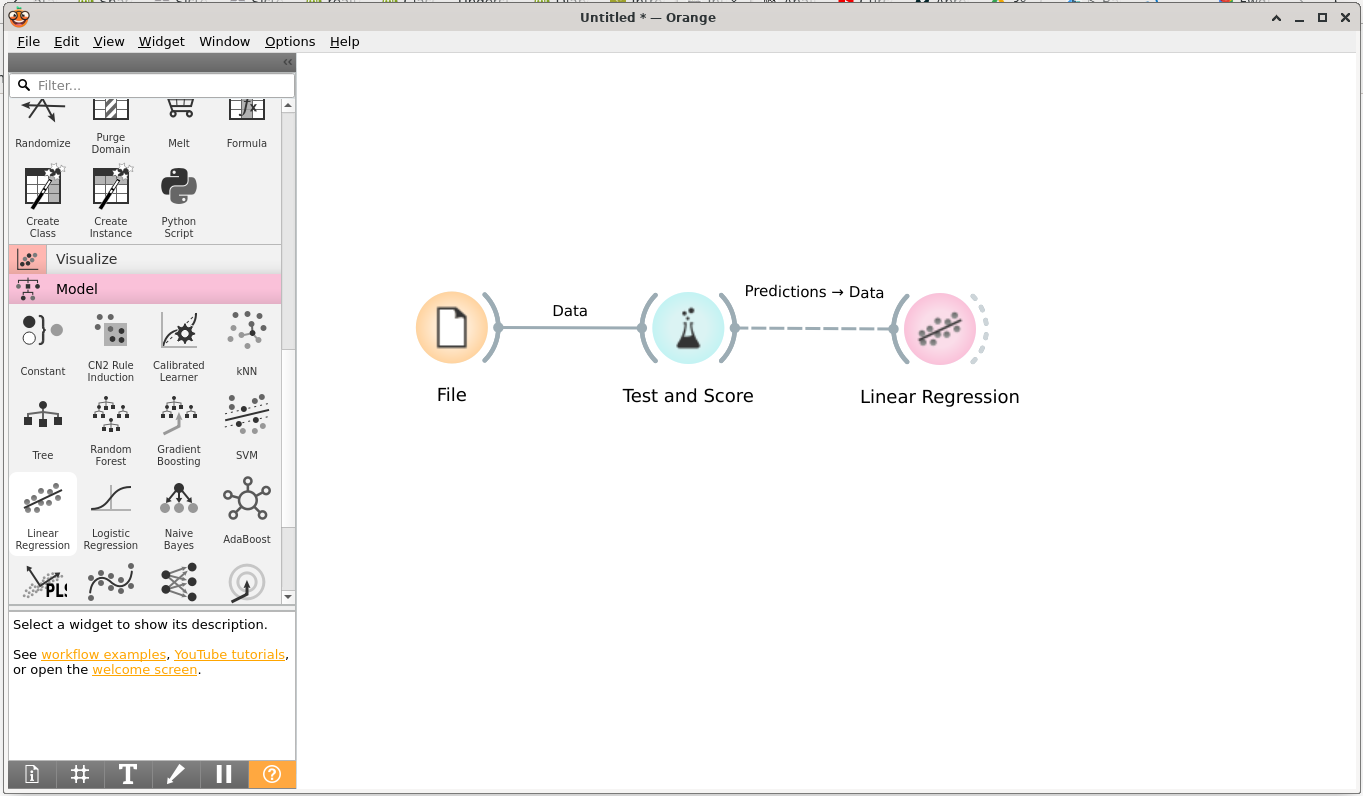
Flujo de trabajo de un ejemplo de regresión linea
Según qué archivo de datos se elija los resultados serán, obviamente, diferentes. Por ejemplo, vamos a utilizar el archivo housing.tab haciendo doble clic en el widget File. Podemos definir como target o variable de salida cualquiera de las 14 opciones que hay disponibles. Por defecto viene la variable MEDV, que se corresponde con el valor medio de las viviendas ocupadas por sus propietarios en unidades de 1000 $. Al realizar el flujo de trabajo descrito anteriormente, podemos hacer doble clic en el widget Test and Score, que nos muestra cómo de bien es capaz de predecir el modelo el valor de la variable mediante las cantidades estadísticas Mean Squared Error (MSE), que en español se traduce como media del error al cuadrado; Root Mean Squared Error (RMSE), que se corresponde con la raíz de la media del error al cuadrado; Mean Absolute Error (MAE), que se traduce como error absoluto medio, y el coeficiente R^2, que es el coeficiente de correlación de Pearson elevado al cuadrado. Nótese que los valores de este último coeficiente cercanos a 1 indican una buena correlación del modelo con los datos con los que ha sido construido.
Como opciones más detalladas, podemos escoger el tipo de validación que podemos realizar, a saber, una validación cruzada, donde el conjunto de datos de entrenamiento y validación varía en el número de iteraciones (number of folds) que el usuario escoja, para hacer finalmente la estadística de los datos. En otro caso puede seleccionarse un muestreo aleatorio, donde escogemos la cantidad aleatoria que conforma el set de entrenamiento y lo separamos del set de validación un determinado número de veces.
1.1.2. Ejercicio
En este ejercicio vamos a comparar el rendimiento de cada uno de los tipos de regresión lineal que permite el entorno Orange. Básicamente, debemos añadir al flujo de trabajo anterior tres modelos de regresión más: Ridge regression, al que vamos a asignar un parámetro α = 0.01, LASSO regression y una Elastic Net regression donde pongamos un parámetro del 50%. Como puede observarse en la figura inferior, al hacer doble clic en el widget Test and Score, se devuelven las mismas cantidades estadísticas del caso anterior para cada uno de los cuatro modelos que hemos asignado. Adicionalmente, Orange devuelve una tabla donde se comparan los modelos utilizando una cantidad estadística concreta, por ejemplo, el Mean Squared Error. Comparando los resultados puede observarse que la Elastic Net regression es el mejor modelo para predecir valores de la variable MEDV en estos datos.
Ver vídeo: https://youtu.be/DjfV0_r4xAw?feature=shared
Referencias
- https://orange3.readthedocs.io/en/3.4.0/widgets/regression/linear.html
- https://orange3.readthedocs.io/projects/orange-visual-programming/en/latest/widgets/model/linearregression.html
- https://orange3.readthedocs.io/projects/orange-visual-programming/en/latest/widgets/evaluate/testandscore.html
- https://orangedatamining.com/home/teach-with-orange/
- https://file.biolab.si/notes/18-baylor/bcm-dm-lecture-5.pdf