- 1. Introducción
- 2. ¿Qué es un Dataset?
- 3. Comprensión de conjuntos de datos
- 4. Crear un conjunto de datos
- 5. Características básicas
- 6. Tipos de campos
- 6.1. Estadísticas de los campos numéricos
- 6.2. Campos categóricos
- 6.3. Campos de fecha-hora
- 6.4. Campos de imagen
- 7. Opciones de configuración del conjunto de datos
- 8. Muestreo
- 8.1. Muestreo avanzado
- 8.1.1. Rango
- 8.1.2. Muestreo
- 8.1.3. Reemplazo
- 8.1.4. Out of Bag
- 8.1. Muestreo avanzado
- 9. Diagrama de dispersión dinámica
- 10. Detector de anomalías
- 11. Características avanzadas
- 11.1. Filtros
- 11.2. Ingeniería de atributos
- 12. Referencias
1. Introducción
- Introducción
- Flujo de trabajo típico: Creación de un conjunto de datos con 1 solo click (1- CLICK DATASET).
- Propósito de los datasets en BigML.
- Características básicas
- Otras formas de crear datasets
- Crear subconjuntos de datos para el entrenamiento y el test del modelo.
- Opciones avanzadas:
- Filtrar conjuntos de datos
- Ingeniería de atributos (Feature engineering) con Flatline.
Recomiendo tener a mano este manual en PDF Datasets with the BigML Dashboard
2. ¿Qué es un Dataset?
Entonces, ¿Qué es un conjunto de datos?
- Los conjuntos de datos son el bloque de construcción fundamental de todos los recursos:
- Los modelos, clusters (agrupamiento), etc. derivan de datasets.
- Los datasets se crean desde las fuentes (sources), normalmente, una vez creado el dataset no volverás atrás a la fuente de datos a no ser que necesites cargar datos nuevos.
- Exploración de datos y visualizaciones para verificarlos antes de aplicar cualquier modelo ML.
- Recuento de valores ausentes / erróneos.
- Estadísticas de resumidas para revisar de forma rápida la naturaleza de nuestros datos.
- BigML también marca de forma automática los campos que pueden no ser útiles para el análisis predictivo.
- Recuento de valores ausentes / erróneos.
3. Comprensión de conjuntos de datos
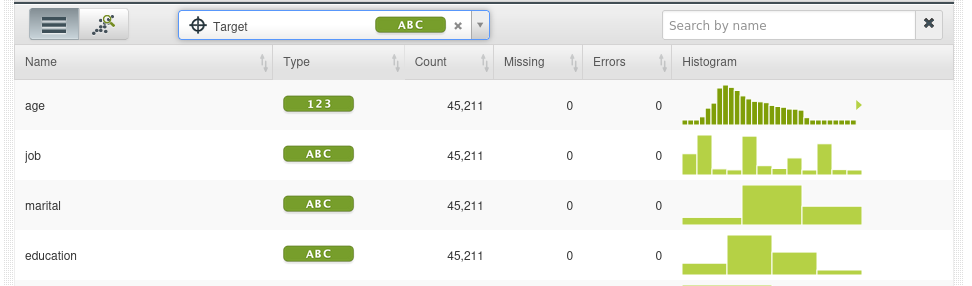
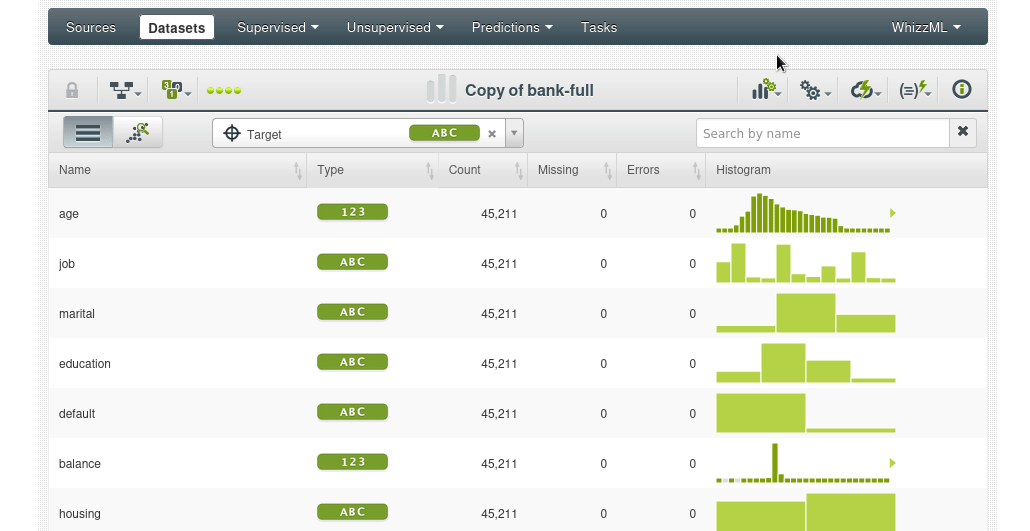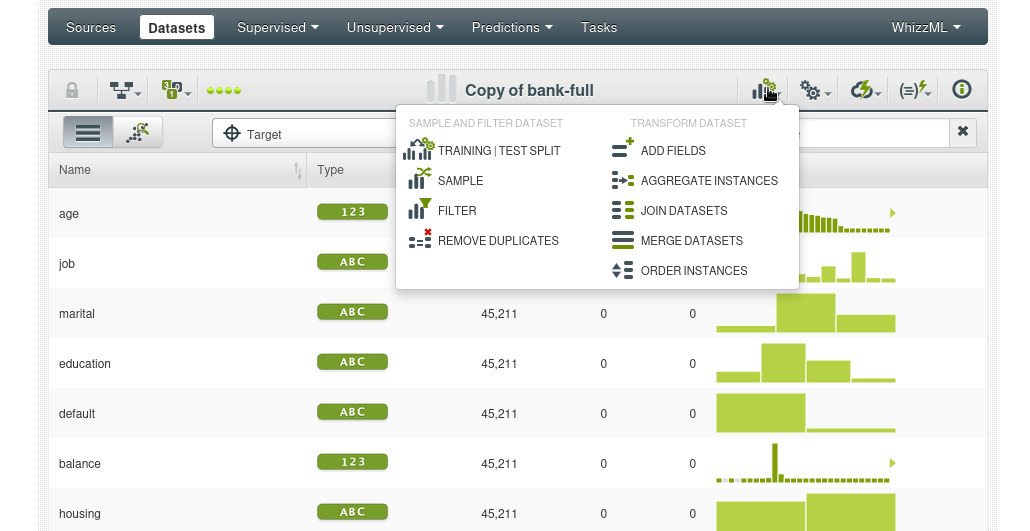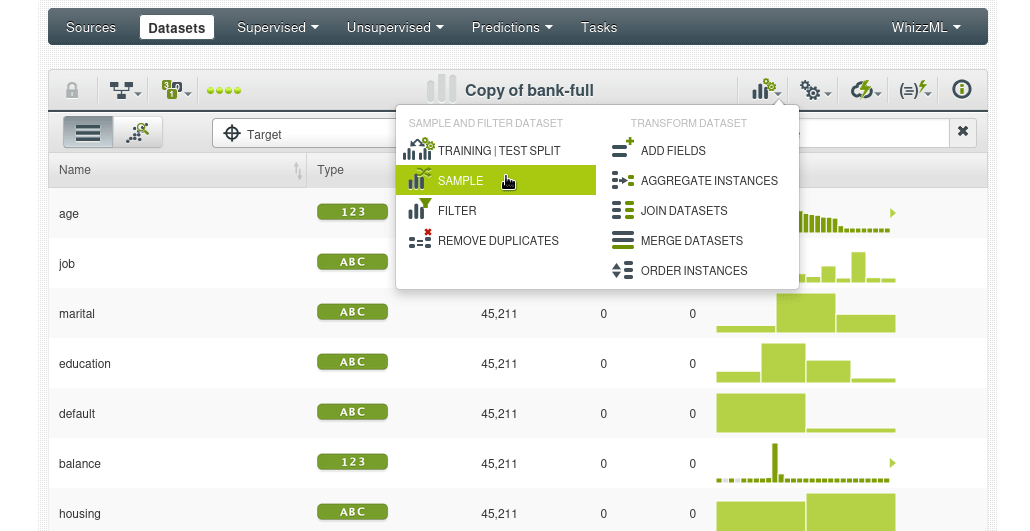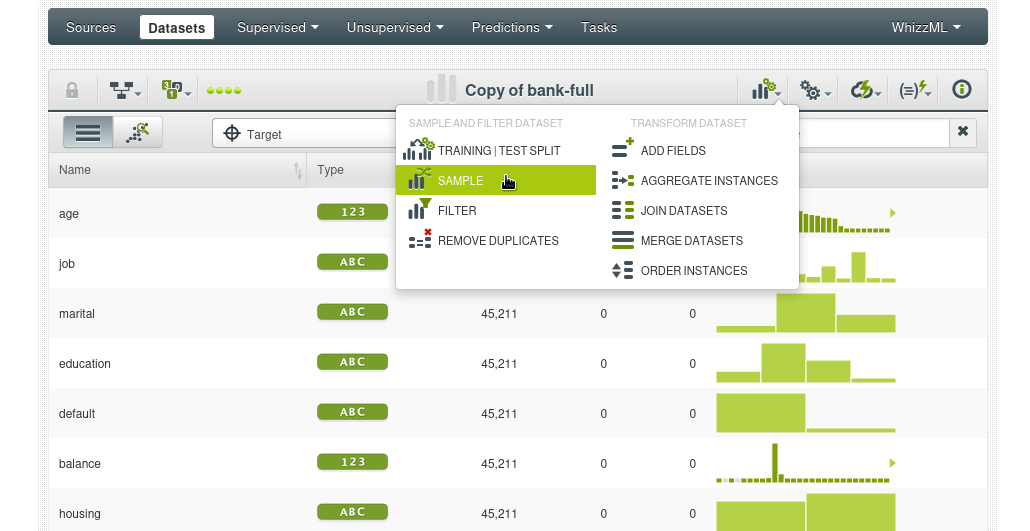
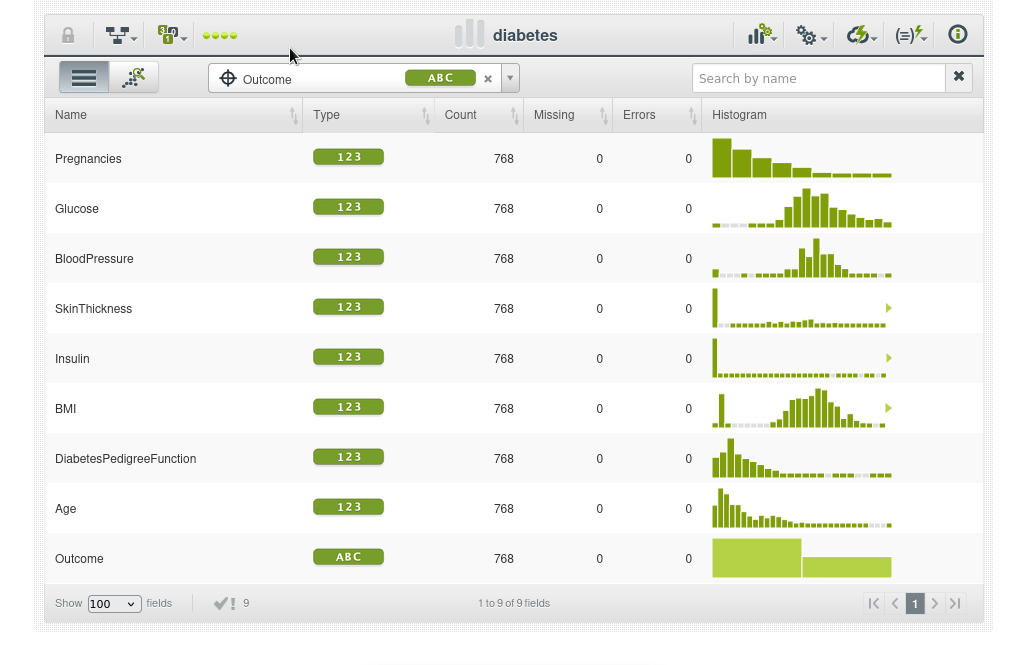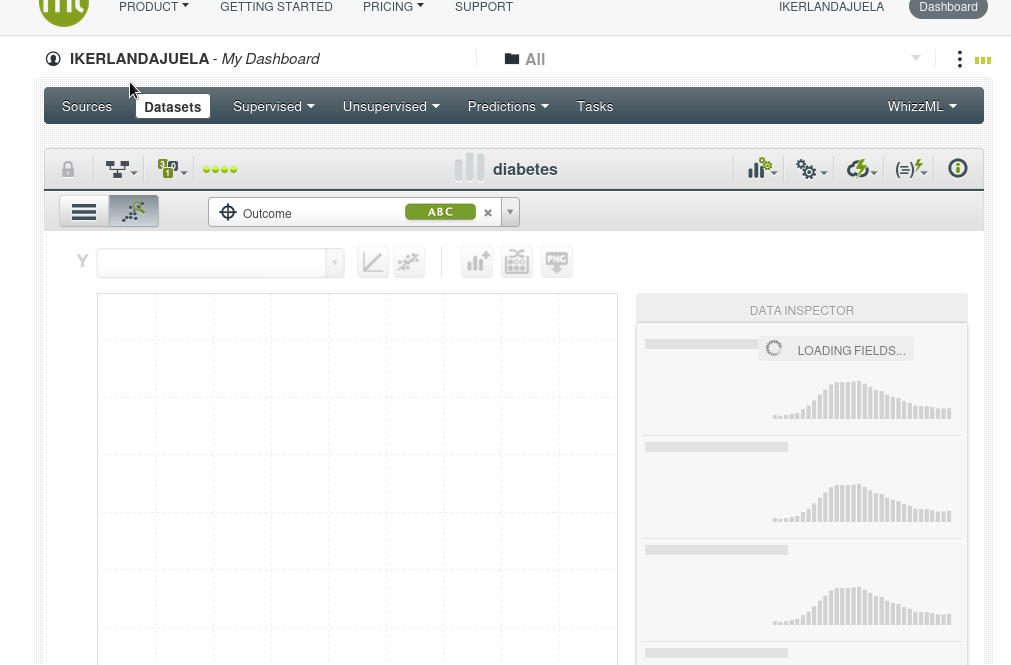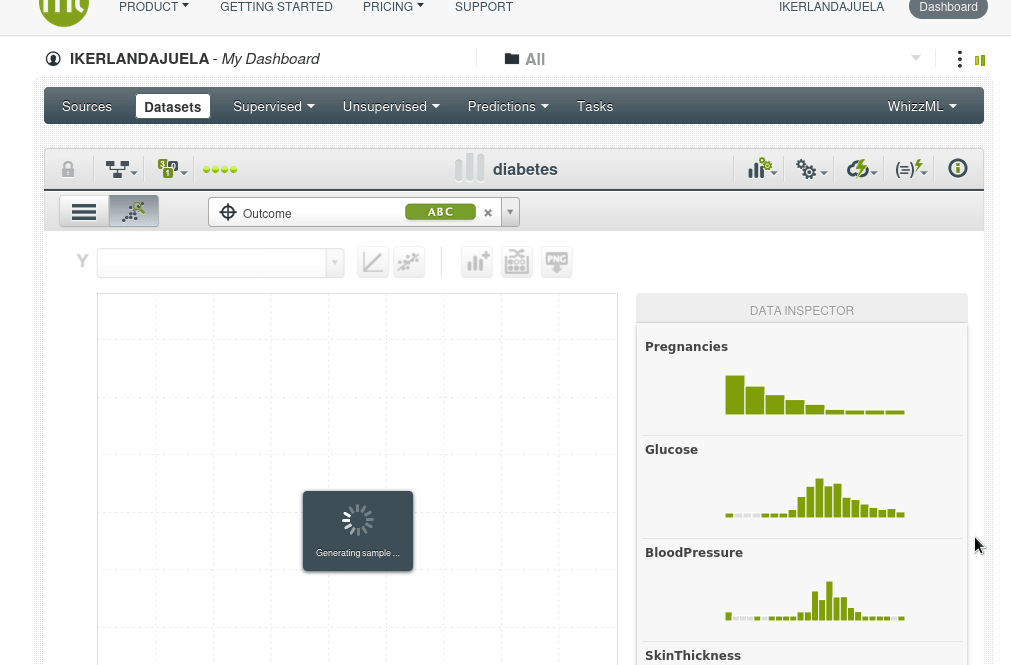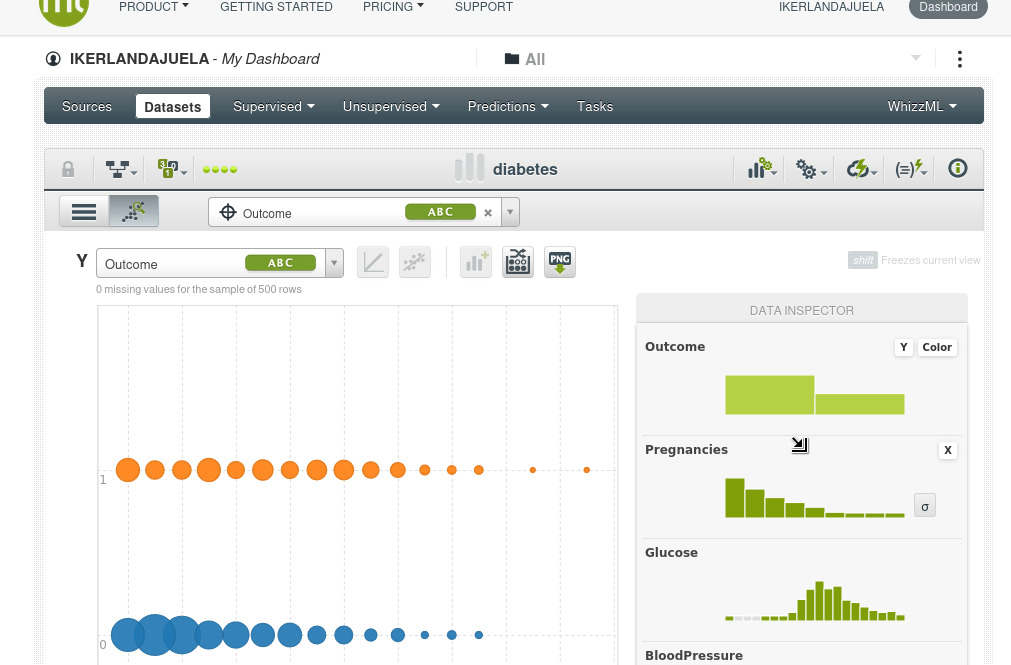
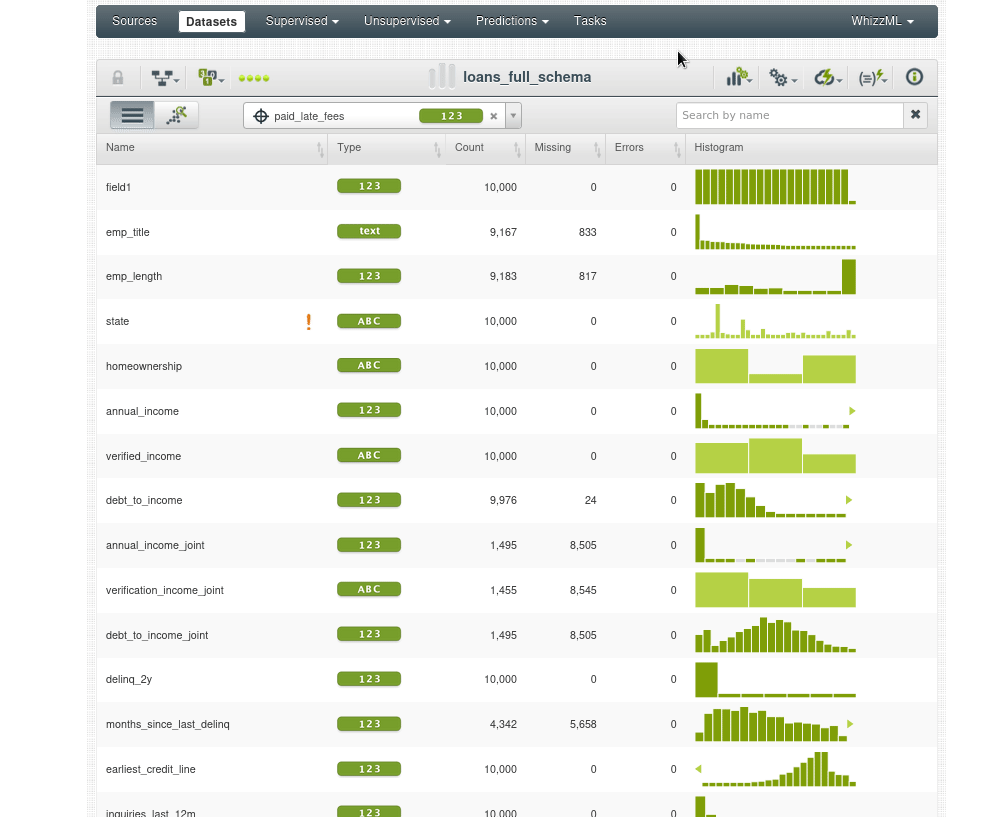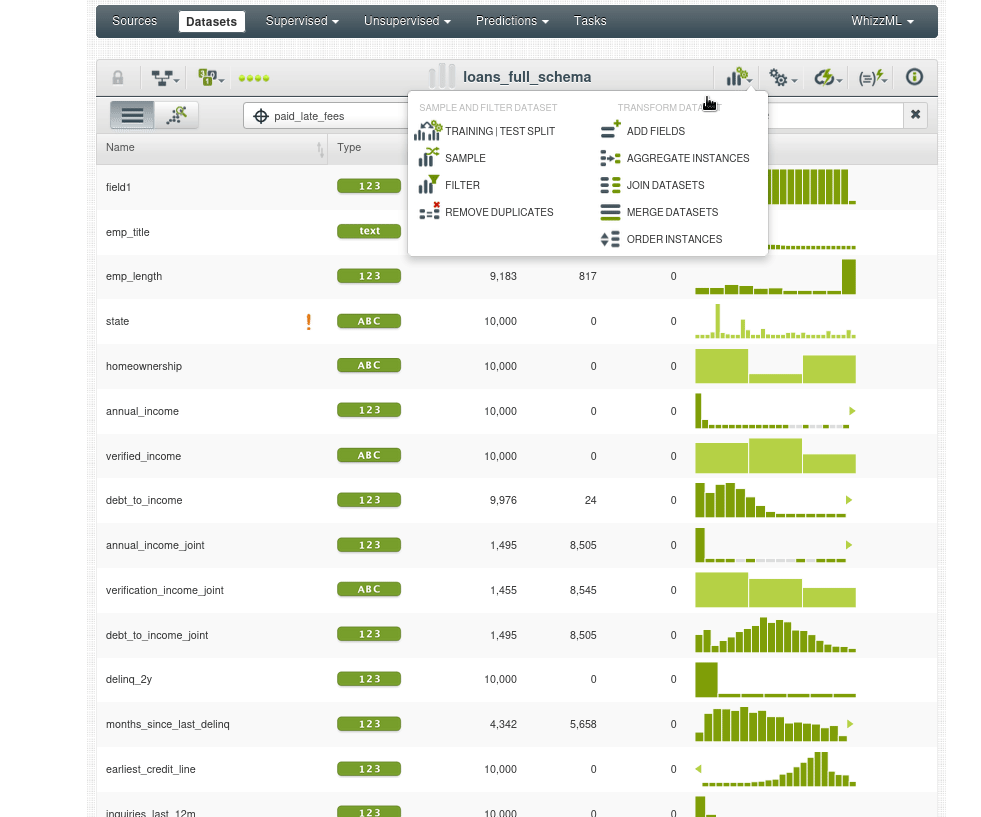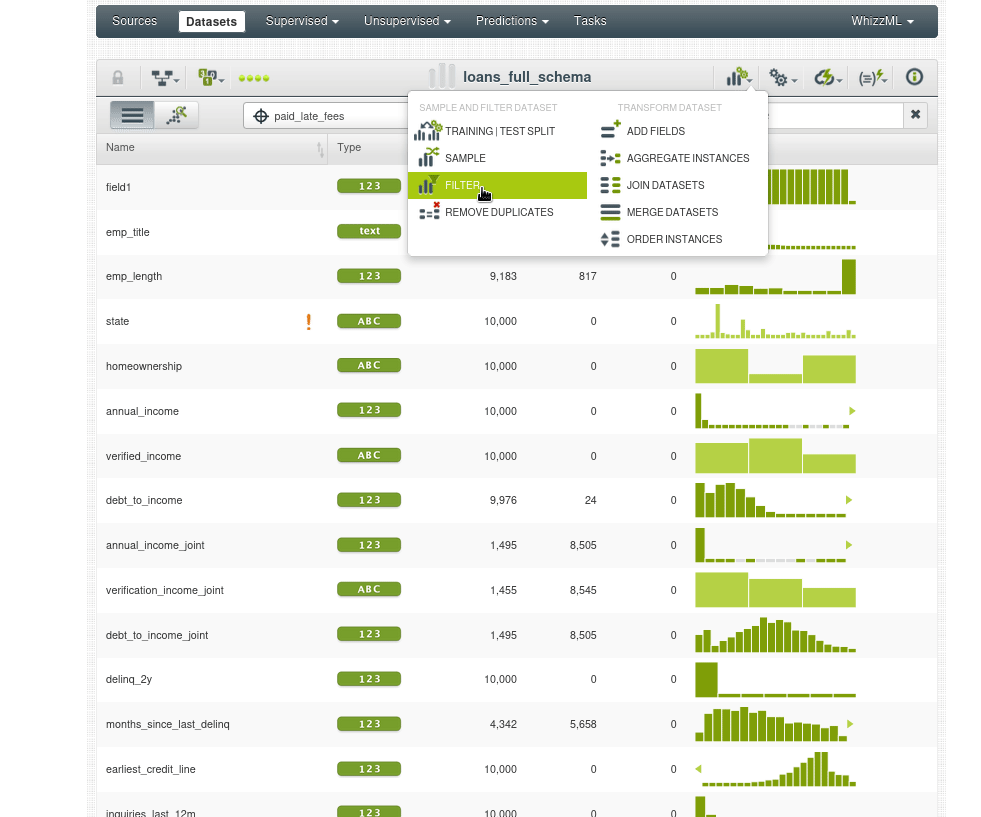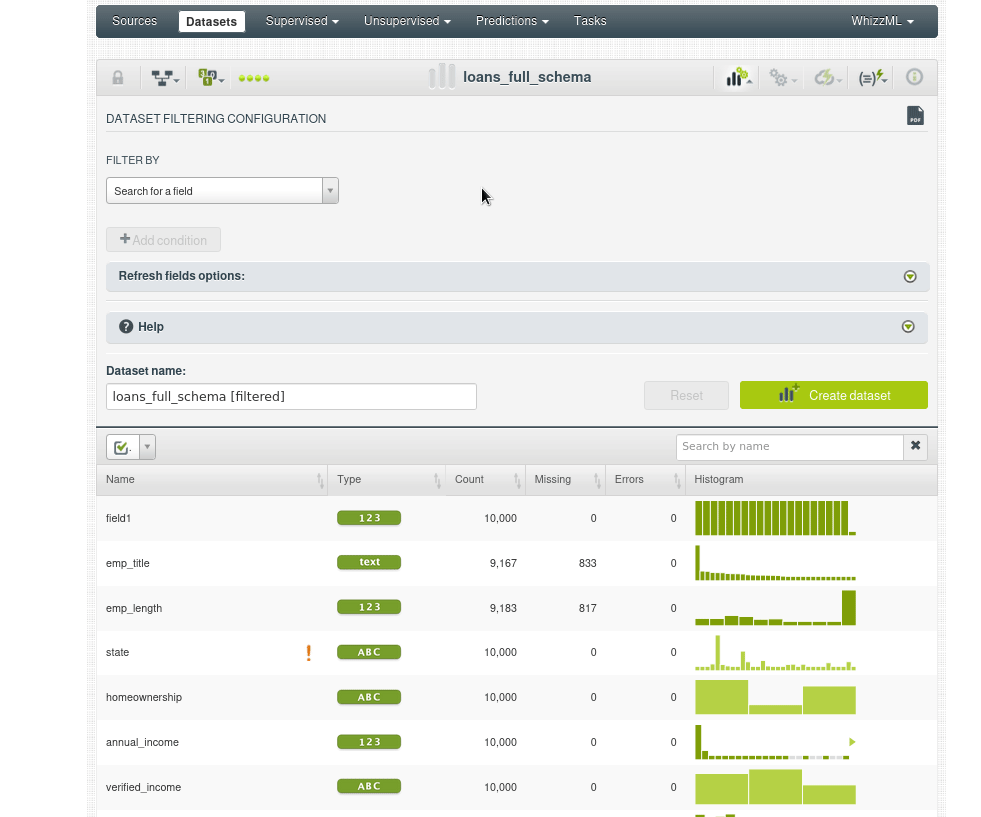
Un conjunto de datos es una versión estructurada de sus datos. BigML calcula tanto estadísticas generales para el conjunto de datos como estadísticas individuales por campo. La figura muestra cómo BigML enumera todos los campos, el tipo de campo y las estadísticas generales, incluyendo:
- Recuento: número de casos que contienen datos para este campo.
- Falta: el número de instancias que carecen de valor para este campo.
- Errores: información sobre campos mal formateados que incluye los errores de formato totales para el campo y una muestra del toke mal formateado
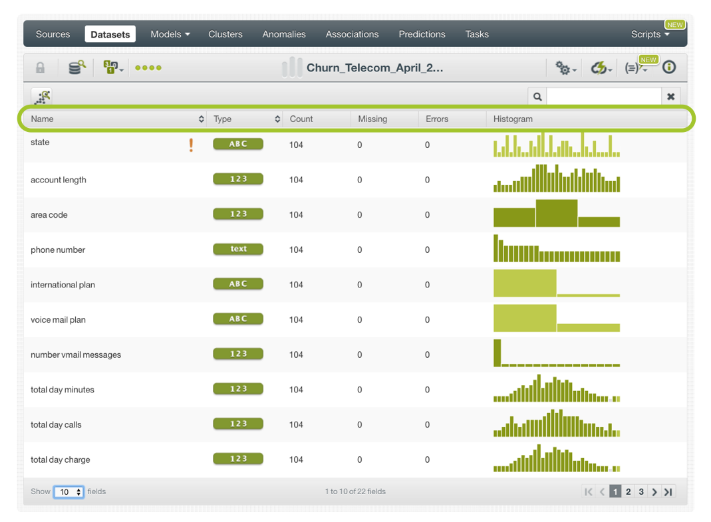
Vista básica de un dataset
Los histogramas comunican las distribuciones subyacentes de sus datos. Dependiendo del tamaño de su conjunto de datos y del número de valores únicos, estos histogramas pueden ser exactos o pueden ser aproximaciones. Lea este blog post para más detalles BigML’s Fancy Histograms.
4. Crear un conjunto de datos
Vamos a crear un dataset usando la acción de 1 clic. Se puede hacer desde dos lugares, desde la vista de lista de todas las fuentes usando el menú a la derecha de cada título, o con la fuente vista en detalle usando el icono de la nube.
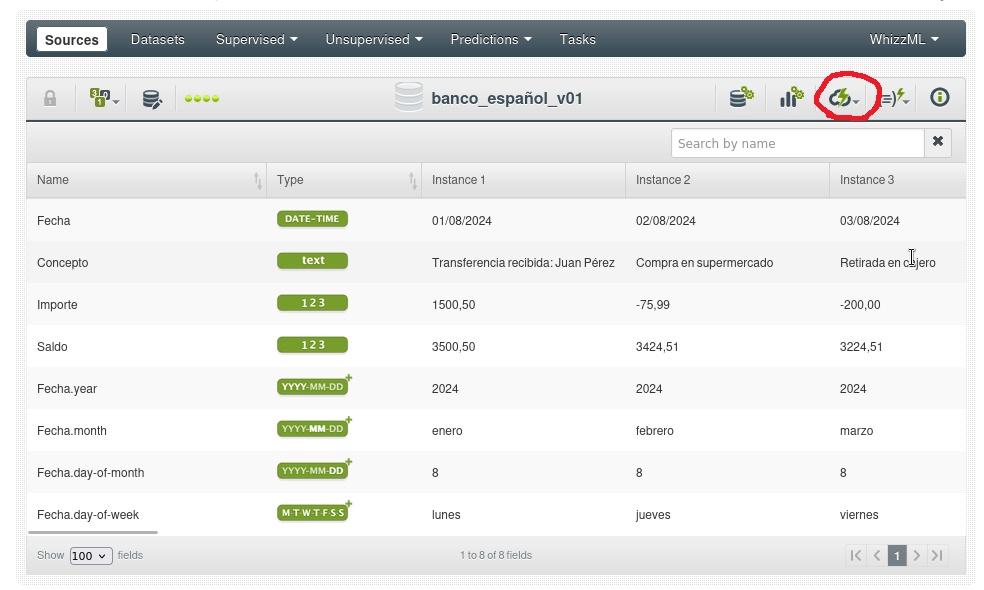
Dataset recién creado:
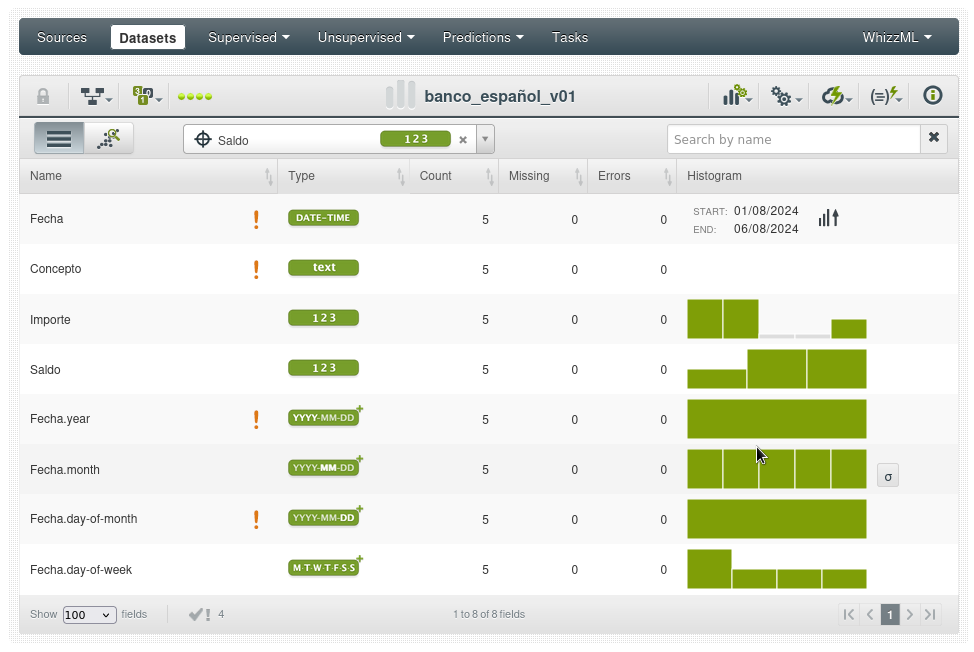
Cada campo tiene un ID asociado (principalmente para la API) que nos permite cambiar el nombre del campo sin ninguna repercusión, usa el icono del lápiz junto al nombre de cada campo:
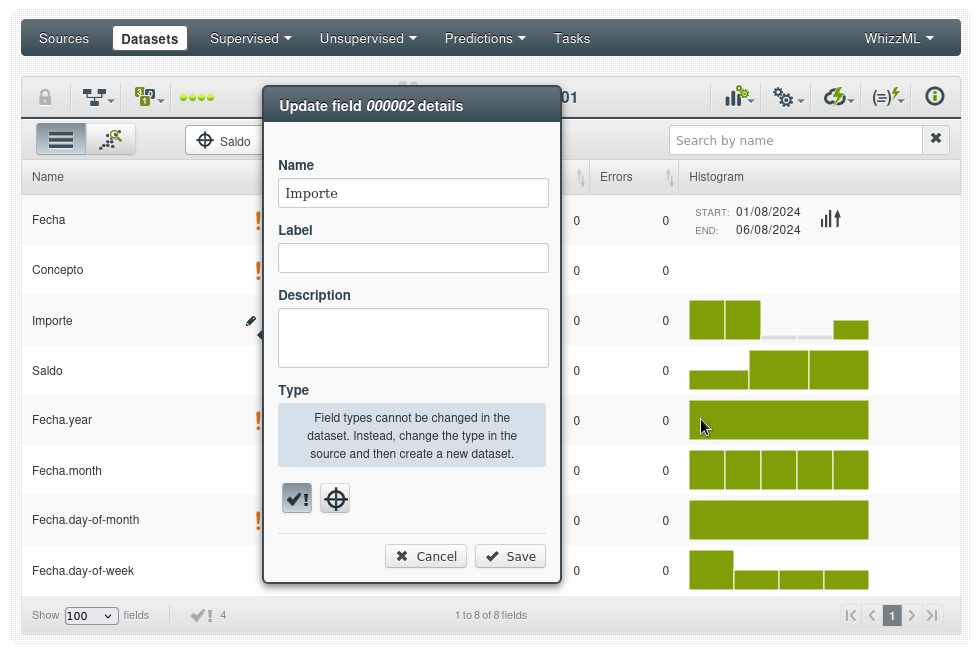
Podemos incluso agregar metadatos (excepto el tipo de datos que sólo se puede hacer en la fuente), podemos indicar si el campo es bueno para realizar las tareas ML o si es la variable objetivo que queremos predecir.
Siguiendo a la derecha, junto al tipo de podemos ver el número de filas que este campo contiene, datos ausentes o erróneos (por ejemplo que aparezca una cadena en lugar de un número).
El diagrama es un histograma que la frecuencia de cada uno de los valores representados.
Un nuevo ejemplo: bank-full.csv

De los 45211 clientes del banco 27214 están casados
Si es un valor numérico también tenemos los resultados del análisis univariado estándar: Mínimo, media, mediana, máximo, desviación estándar, curtosis, asimetría.
Para los campos de texto podemos visualizar una nube de palabras:
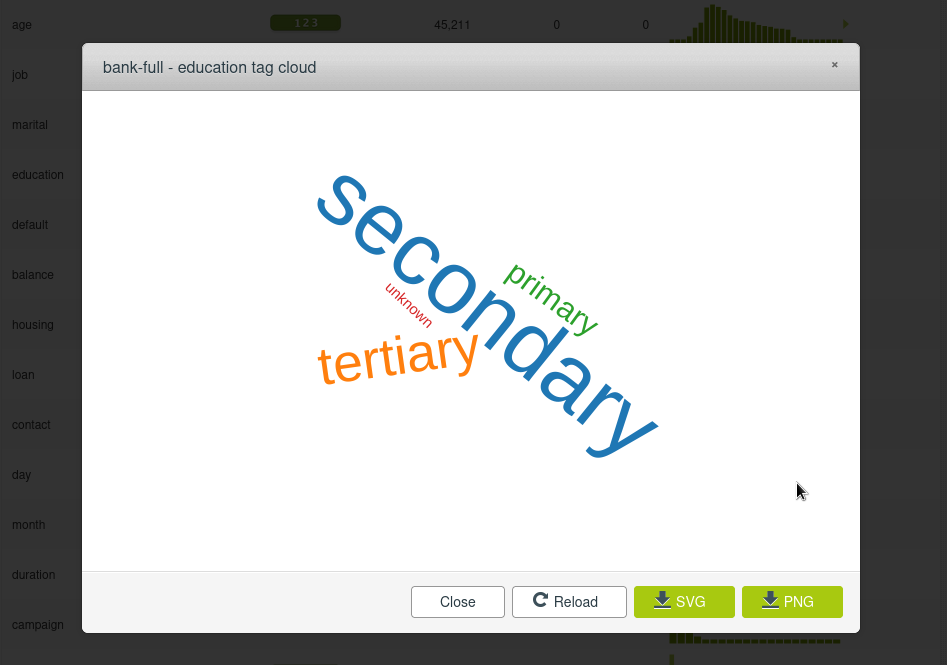
Los pequeños signos de exclamación rojos marcan el campo como no preferido, lo que significa que probablemente no sean útiles para el análisis predictivo y se ignorarán (por ejemplo campos con muchos valores todos distintos como un ID de empleado, clave primaria de una tabla, o textos largos que no siguen un patron de variable discreta).

Se puede ver en el histograma que el campo pdays por ejemplo toma prácticamente sólo un valor.
Hay dos formas de solucionar este problema. La primera es que podemos anular el estado de no preferido cambiando la configuración en el campo metadatos (icono lápiz junto al nombre del campo).
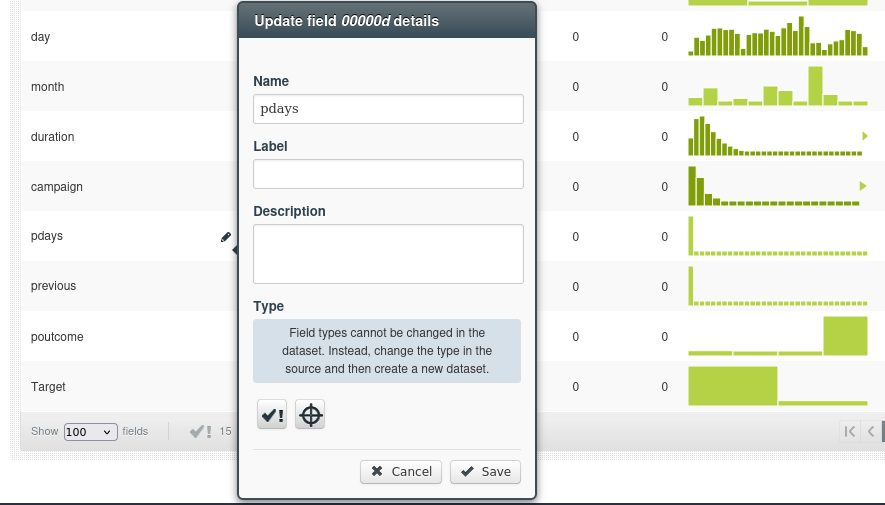
La segunda forma que podemos cambiar esto es cambiando el tipo de campo para que BigML lo trate de otra forma (en la fuente).
Otro cambio importante que podemos hacer es el objetivo predeterminado, es el campo que el modelo tratará de predecir:
5. Características básicas
- Inmutable: Una cosa importante es entender que los valores de los datos son inmutables, es decir, no se pueden cambiar una vez crean. Para poder solventar este “problema”, siempre podremos crear nuevos datasets.
- Crear dataset
- Desde una fuente.
- Desde un dataset: aplicando un filtro, realizando una división entre datos de entrenamiento y prueba.
- Dynamic Scatterplot: Visualización de un diagrama de dispersión dinámico.
Si la fuente es muy grande (puede darnos problemas con la suscripción gratuita por ejemplo) podemos reducir su tamaño en la fuente:
Archivo CSV para los ejemplos de muestro: sampling_test_01.csv
6. Tipos de campos
6.1. Estadísticas de los campos numéricos
BigML calcula las medidas siguientes en base a todos los casos de un campo numérico determinado y muestra estas medidas en un histograma.
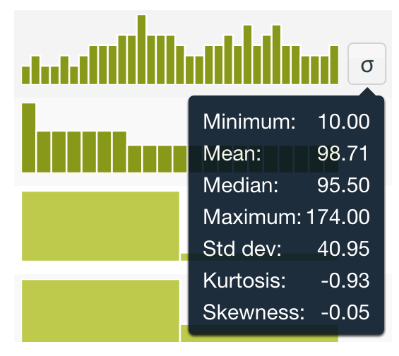
6.1.1. Mínimo
Mínimo: el valor mínimo encontrado en este campo numérico.
Ejemplo: Si un conjunto de datos incluye los valores 3, 7, 2, y 5, el mínimo sería 2.
6.1.2. Media
Media: la media aritmética de los valores del campo que no están ausentes.
Ejemplo: Para los valores 4, 6, y 8, la media se calcula como (4 + 6 + 8) / 3 = 6.
6.1.3. Mediana
La mediana representa el valor de la variable de posición central en un conjunto de datos ordenados. Se le denota mediana.
Ejemplo: En el conjunto de datos 3, 1, 4, 2, y 5, al ordenarlos (1, 2, 3, 4, 5), la mediana es 3, ya que es el valor del medio.
6.1.4. Desviación estándar
Desviación estándar: Mide la dispersión de los valores respecto a la media. Una desviación estándar baja indica que la mayor parte de los datos de una muestra tienden a estar agrupados cerca de su media (también denominada el valor esperado), mientras que una desviación estándar alta indica que los datos se extienden sobre un rango de valores más amplio.
Ejemplo: En un conjunto de datos donde los valores son 2, 4, y 6, la desviación estándar indica qué tan lejos están los valores de la media (4).
6.1.5. Curtosis
Curtosis: la curtosis de la muestra. Es una medida de “agudeza” o colas pesadas en la distribución del campo.
Ejemplo: Una alta curtosis indica que hay más valores extremos en la distribución, mayor número de valores de la variable muy dispersos y muy lejos del centro de la misma (es decir, en las colas), lo que significa que hay colas más pesadas en comparación con una distribución normal.
6.1.6. Asimetría
Asimetría: Es una medida de la asimetría en la distribución del campo.
Ejemplo: Si una distribución tiene una cola más larga hacia la derecha, se considera asimétrica a la derecha (positiva); si tiene una cola más larga hacia la izquierda, se considera asimétrica a la izquierda (negativa).
6.2. Campos categóricos
BigML crea un bin por etiqueta contenido en un campo categórico. Cada contenedor contiene el número de casos que tienen una etiqueta específica, el ejemplo que se muestra en la figura tiene seis etiquetas, por lo que el el histograma muestra seis bins, y 245 casos de este campo son etiquetados como “España”.
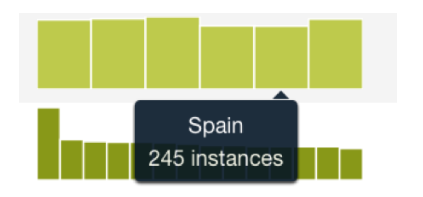
Nota: cuando BigML encuentra campos formateados binarios (todos los valores 0 o 1), los trata como categóricos en lugar de numéricos. Puede sobreponerse a este valor predeterminado en la configuración de origen.
6.3. Campos de fecha-hora
BigML expande cada campo de fecha-hora en hasta ocho campos numéricos, por ejemplo día de la semana, día del mes, etc. Puede habilitar o desactivar la generación automática al cambiar la opción de campos de tiempo de fecha de expansión en el menú de fuente de configurar. Cuando estén deshabilitados, los campos potenciales de fecha-hora se tratarán como campos categóricos o de texto.
Estos campos expandidos son tratados como campos numéricos; por lo tanto, BigML calcula las mismas estadísticas mencionadas anteriormente para el campo numérico.

Ejemplo de campos numéricos generados automáticamente a partir de un campo de tiempo
6.4. Campos de imagen
Para cada imagen de un conjunto de datos, hay al menos dos campos asociados a ella. El campo con un tipo de imagen apunta a la versión normalizada del archivo de imagen en sí, mientras que el campo con un tipo de ruta representa su nombre de archivo. En el campo de imagen, los usuarios pueden obtener una vista previa de las imágenes en su columna “Histograma”
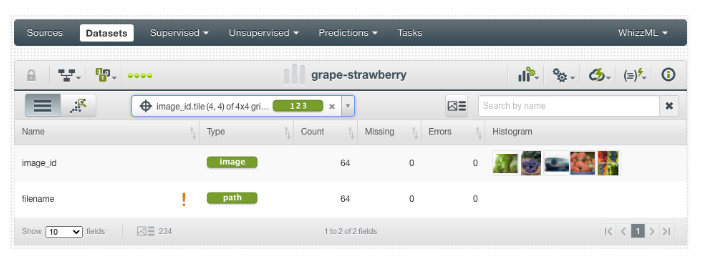
6.4.1. Subir un dataset con imágenes en BigML
En lugar de subir las imágenes directamente, deberás crear un archivo CSV que contenga las rutas de las imágenes y cualquier otra información relevante. Por ejemplo:
image_path,label
hairless.png,clase1
tabby.png,clase2
La primera columna es la ruta de la imagen, podemos comprimir el conjunto de imagenes y el archivo de texto csv de arriba y subirlo a BigML como una fuente de datos.
7. Opciones de configuración del conjunto de datos
Además de la opción de un solo clic para crear un conjunto de datos, BigML también le permite configurar su conjunto de datos asignándole un nombre diferente y seleccionando el porcentaje de su fuente que se utilizará para crear el conjunto de datos. También puede incluir o excluir ciertos campos según lo desee. Las siguientes subsecciones cubren las opciones disponibles
7.1. Nombre del conjunto de datos
Al hacer clic en la opción de menú CONFIGURAR CONJUNTO DE DATOS, en la vista de origen que desea utilizar para crear su conjunto de datos, obtendrá acceso al panel de configuración del conjunto de datos. Cambie el nombre predeterminado proporcionado por BigML escribiendo un nuevo nombre en el cuadro de nombre del conjunto de datos
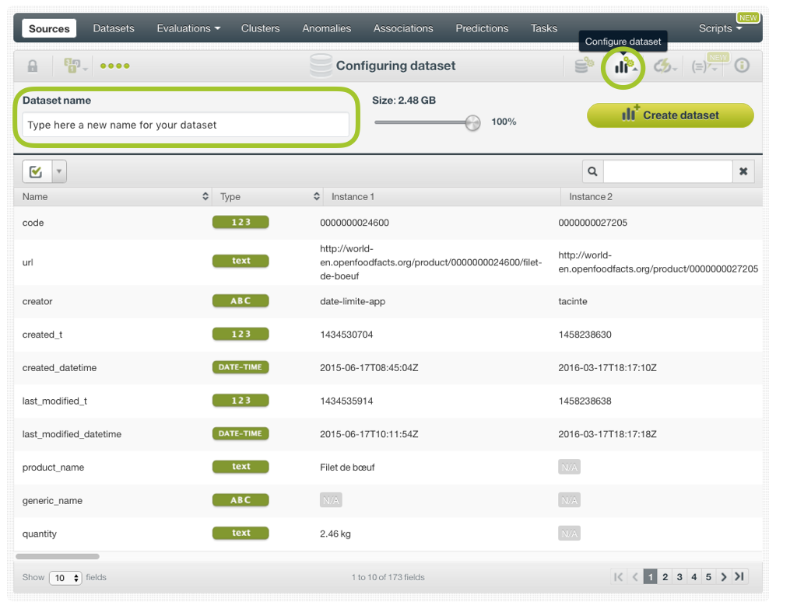
Panel de configuración para asignar un nuevo nombre a su conjunto de datos
7.2. Tamaño del conjunto de datos
De manera predeterminada, BigML utiliza todos los datos que tiene en su fuente. Sin embargo, cuando trabaja con grandes conjuntos de datos, puede acelerar la exploración de sus datos reservando un subconjunto de su fuente y creando su conjunto de datos con solo una pequeña parte de sus datos. Seleccione el porcentaje que desea utilizar para crear su conjunto de datos moviendo el control deslizante de tamaño resaltado en la figura inferior. En este ejemplo, estamos utilizando el 10 % de la fuente importada a BigML.
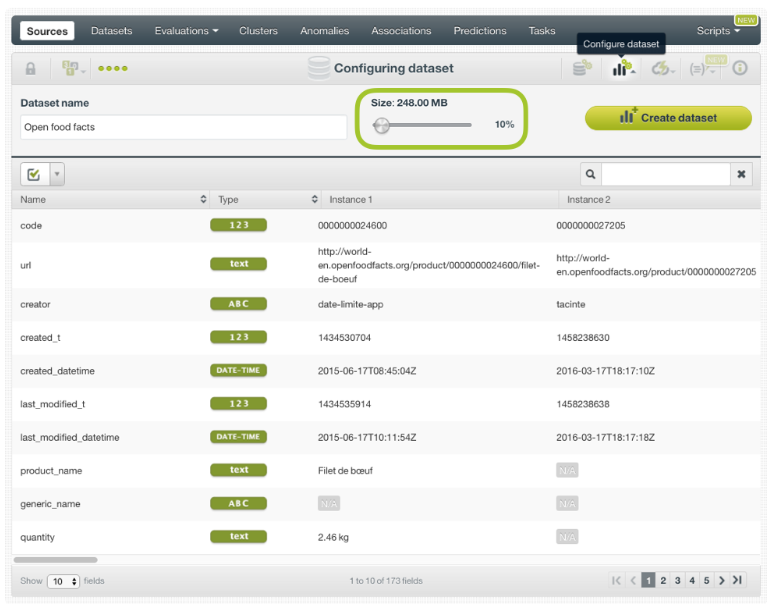
Panel de configuración para seleccionar el tamaño de tu fuente
Esta opción no está disponible cuando la fuente contiene imágenes. Sin embargo, siempre puede utilizar el muestreo después de crear el conjunto de datos.
7.3. Inclusión o exclusión de campos
Las opciones de configuración del conjunto de datos le permiten incluir o excluir campos al crear un conjunto de datos. Puede incluirlos o excluirlos todos, como se ve en la figura. O desmarcar la casilla asociada con los campos que no desea utilizar, como se muestra en la segunda figura. Los campos que desmarque no se incluirán en el conjunto de datos, por lo tanto, BigML no los considerará cuando cree su modelo más adelante.
Obviamente, si excluye todos sus campos, no se creará ningún conjunto de datos. Sin embargo, esta opción puede ser útil cuando su fuente tiene muchos campos pero solo desea incluir algunos de ellos. En este caso, sería más rápido excluirlos todos y seleccionar los pocos campos que desea incluir uno por uno.
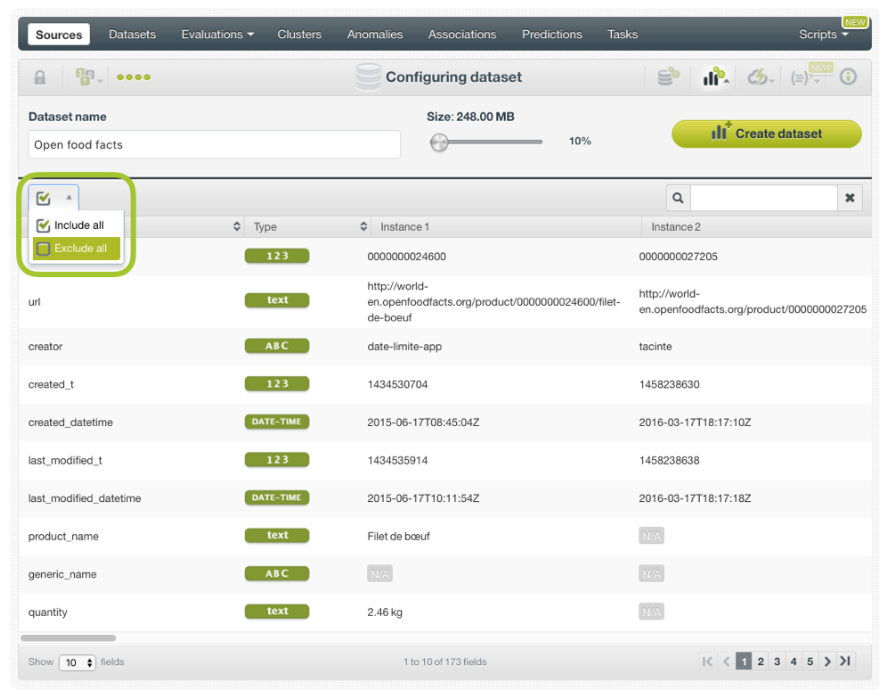
Panel de configuración para incluir y excluir campos
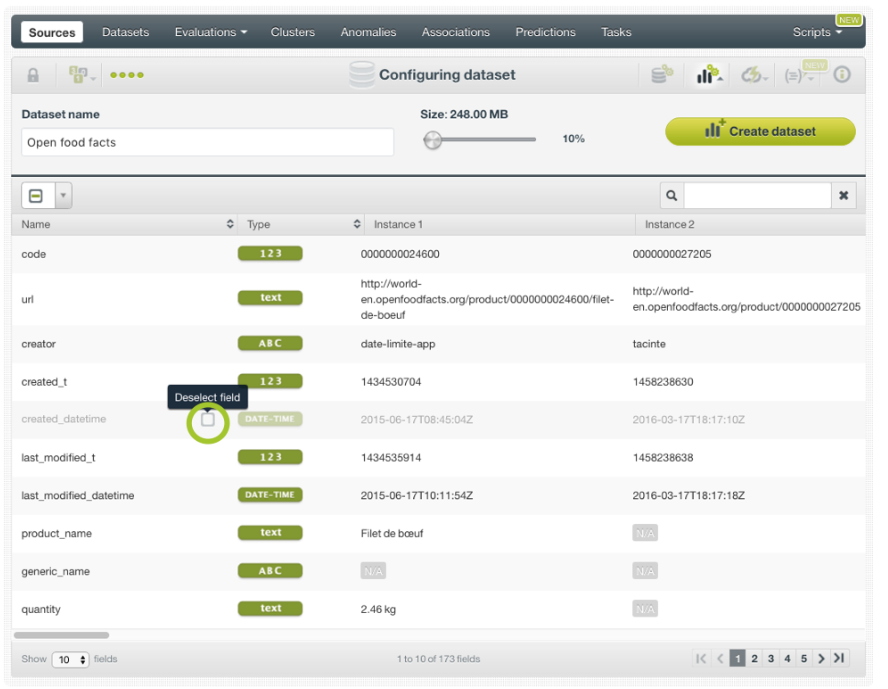
Ejemplo de un campo deseleccionado
Una vez que haya asignado un nuevo nombre a su conjunto de datos, haya establecido el porcentaje de su fuente a utilizar y haya seleccionado los campos que necesita, estará listo para hacer clic en el botón Crear conjunto de datos
8. Muestreo
También podemos obtener un muestreo (sample) de un dataset:
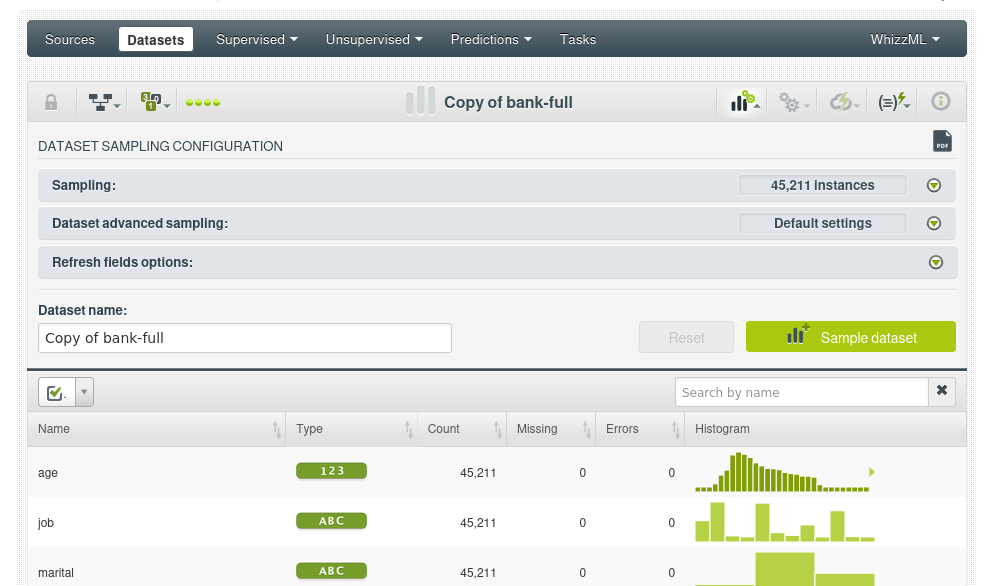
La primera opción controla el porcentaje del archivo a muestrear, de forma predeterminada será una muestra aleatoria.
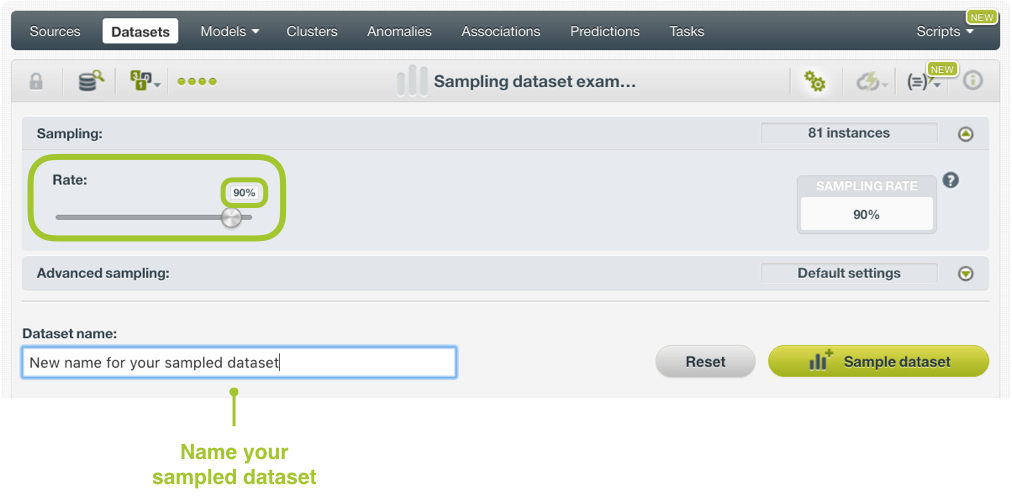
8.1. Muestreo avanzado
En el muestreo avanzado, es posible cambiar a una muestra determinista, lo que significa que se usa un valor fijo para el muestreo, esto hace que la muestra sea repetible.
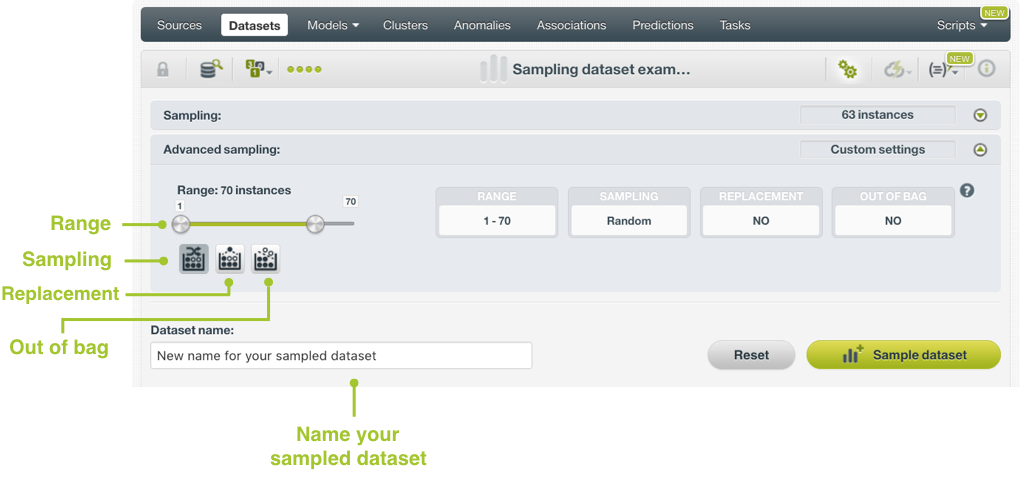
8.1.1. Rango
Especifique un subconjunto de instancias. Por ejemplo, elija una gama de ejemplos 100 a 200. La tasa especificada se aplicará sobre el subconjunto configurado. Esta opción puede ser útil cuando tienes datos temporales, y quieres entrenar tu modelo con datos históricos y probarlo con el más reciente para verificar si puede predecir en función del tiempo.
8.1.2. Muestreo
Por defecto, BigML selecciona sus instancias para la muestra utilizando un generador de números aleatorios, lo que significa que dos muestras del mismo conjunto de datos probablemente serán diferentes incluso cuando se utilicen las mismas tasas y rangos de filas, excepto cuando la tasa es del 100% y no utilicen la repetición. Si elige un muestreo determinista, el generador de números aleatorios siempre utilizará la misma semilla, produciendo resultados repetibles. Esto le permite trabajar con muestras idénticas del mismo conjunto de datos.
8.1.3. Reemplazo
El muestreo con sustitución permite seleccionar una sola instancia varias veces. El muestreo sin sustitución garantiza que cada instancia no puede seleccionarse más de una vez. Por defecto, BigML genera muestras sin sustitución.
8.1.4. Out of Bag
Si una instancia no se selecciona como parte de un muestreo determinista, se considera fuera de bolsa. Esto permitirá seleccionar solo las instancias excluidas (invierte las filas que se mantienen). Esto puede ser útil para dividir un conjunto de datos en subconjuntos de entrenamiento y pruebas. Solo es seleccionable cuando una muestra es determinista y la tasa de muestreo es inferior al 100%.
Por supuesto, al realizar el muestreo puede suceder que los tipos de campo o el estado preferido pueda cambiar, por lo que se puede habilitar la detección automática de estas acciones.

Con el muestreo podríamos dividir el dataset en un conjunto de entrenamiento más grande, por ejemplo el 80%, y un conjunto de test del 20% (con out of bag) para medir el desempeño del modelo, sin que se repitan las filas en los dos conjuntos, por supuesto hay una forma más fácil de hacerlo, BigML proporciona un método de un solo clic (TRAINING | TEST SPLIT).
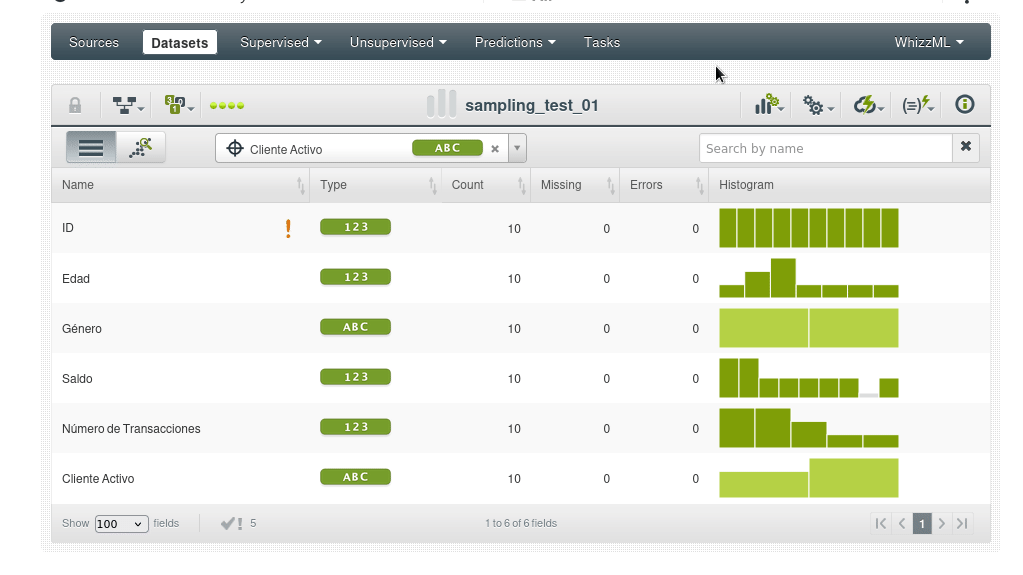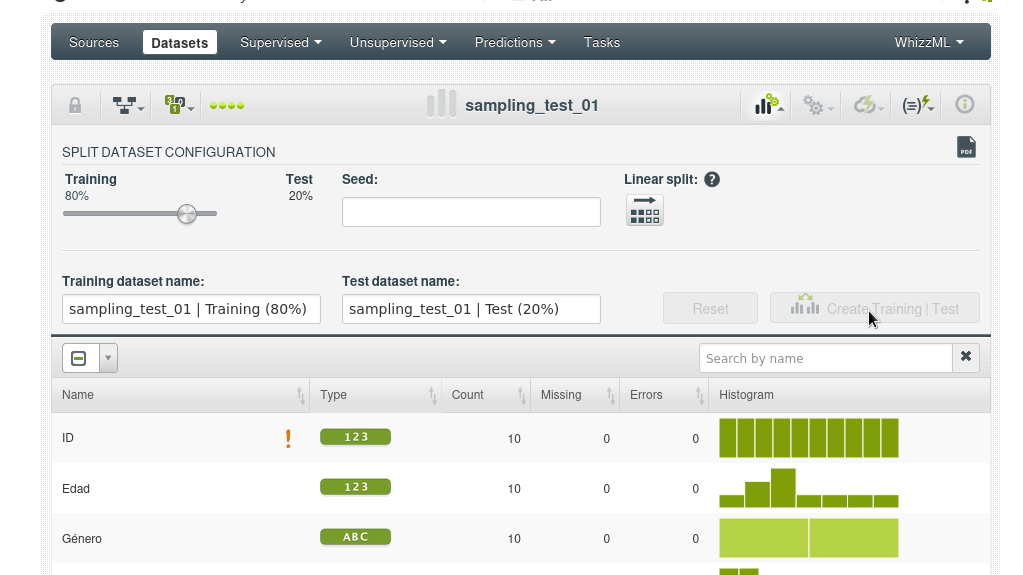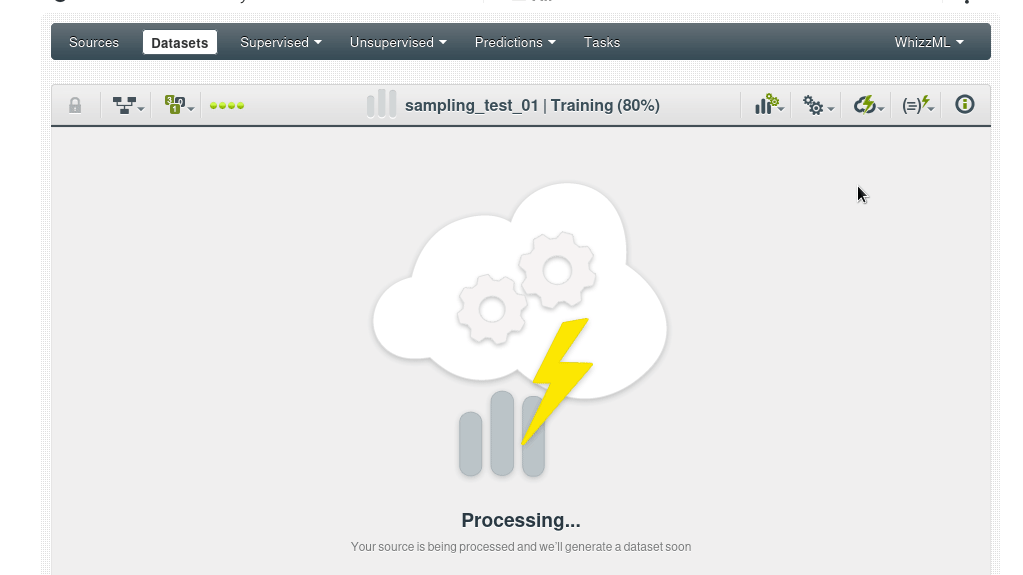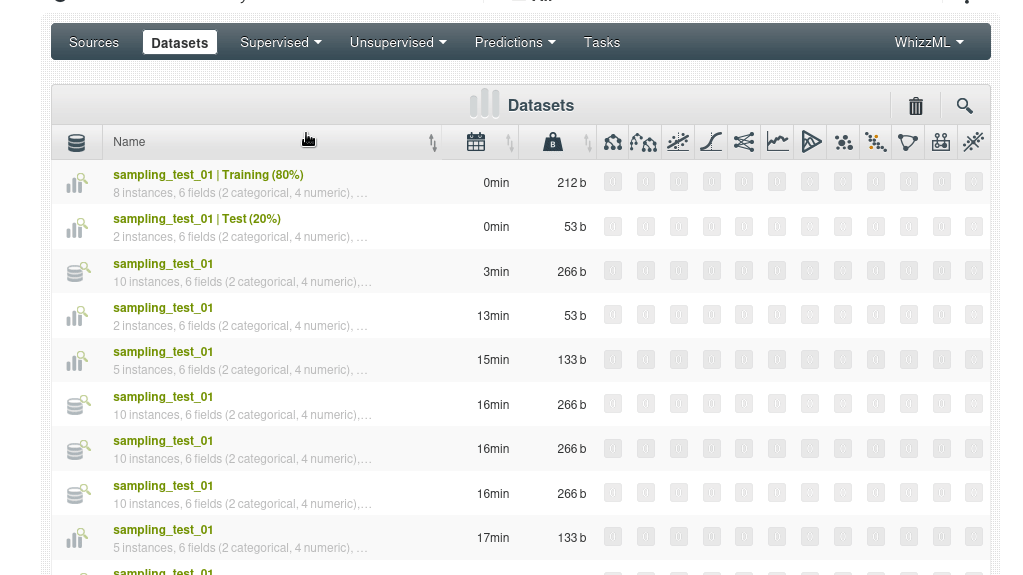
Veremos que la acción genera dos nuevos conjuntos de datos, por supuesto puedes ajustar el porcentaje que toma cada conjunto, puedes definir una semilla específica para usar el el muestreo determinista (una cadena de texto por ejemplo, siempre la misma).
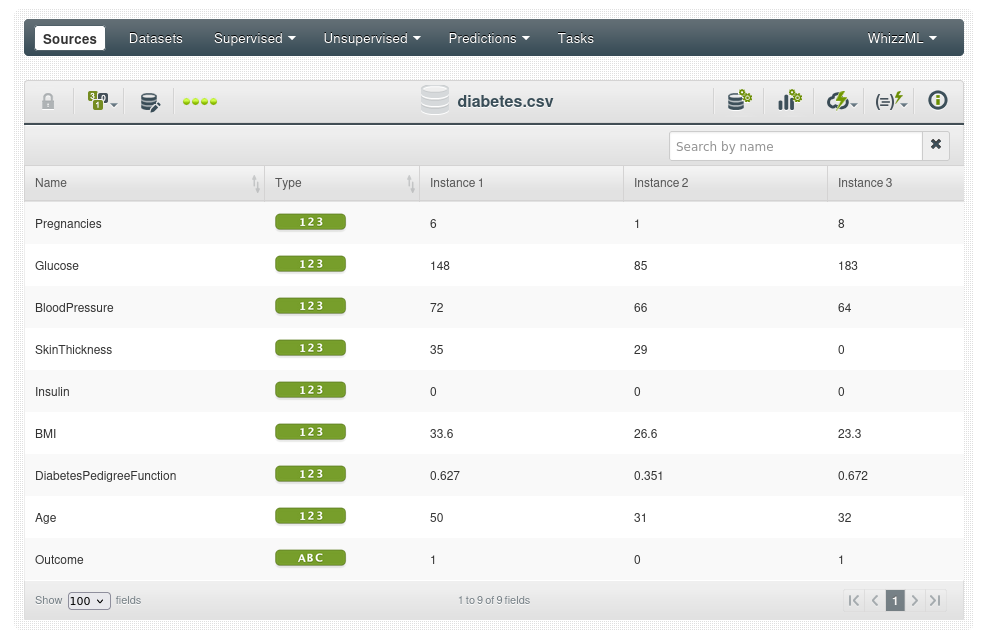
Usaremos este archivo CSV de ejemplo para explorar la salida por lotes y el diagrama de dispersión dinámica: diabetes.csv. El conjunto de datos consta de varias variables predictoras médicas (independientes) y una variable objetivo (dependiente), Outcome. Las variables independientes incluyen el número de embarazos que la paciente ha tenido, su IMC, el nivel de insulina, la edad, etc (ver fuente en Kaggle Pima Indians Diabetes Database).
Con estos datos podríamos construir un modelo predictivo que tratase de predecir con un nuevo caso si el paciente tiene probabilidad de sufrir diabetes o no.
9. Diagrama de dispersión dinámica
Generamos un dataset con un solo clic como hemos visto, desde la vista del conjunto de datos podemos generar un diagrama de dispersión (scatter plot)
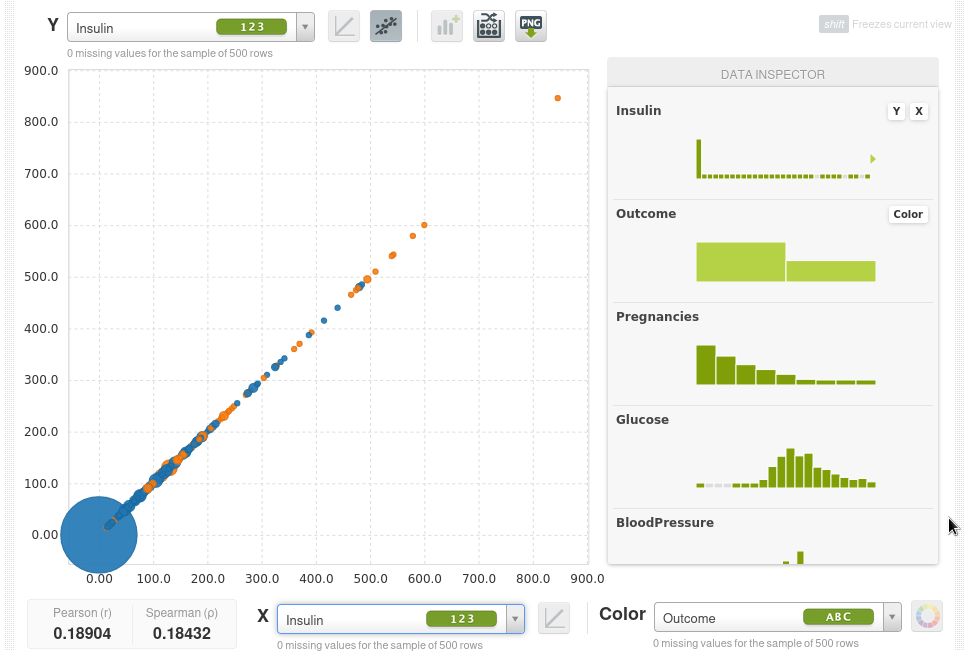
Así que lo que podemos hacer ahora es poner dos características que queramos en las coordenadas X e Y y usar el color para la variable objetivo outcome, por ejemplo el eje Y será el índica de masa corporal BMI, el eje X serán los niveles de glucosa y el color será Outcome. Los puntos azules serán pacientes que no tienen diabetes y los naranjas aquellos que si la tienen, podremos ver de inmediato que a medida que la glucosa aumenta la tasa de diabetes aumenta y también aumenta con el BMI.
El scatter plot toma una muestra de 500 instancias, podemos tomar nuevas muestras de forma interactiva:
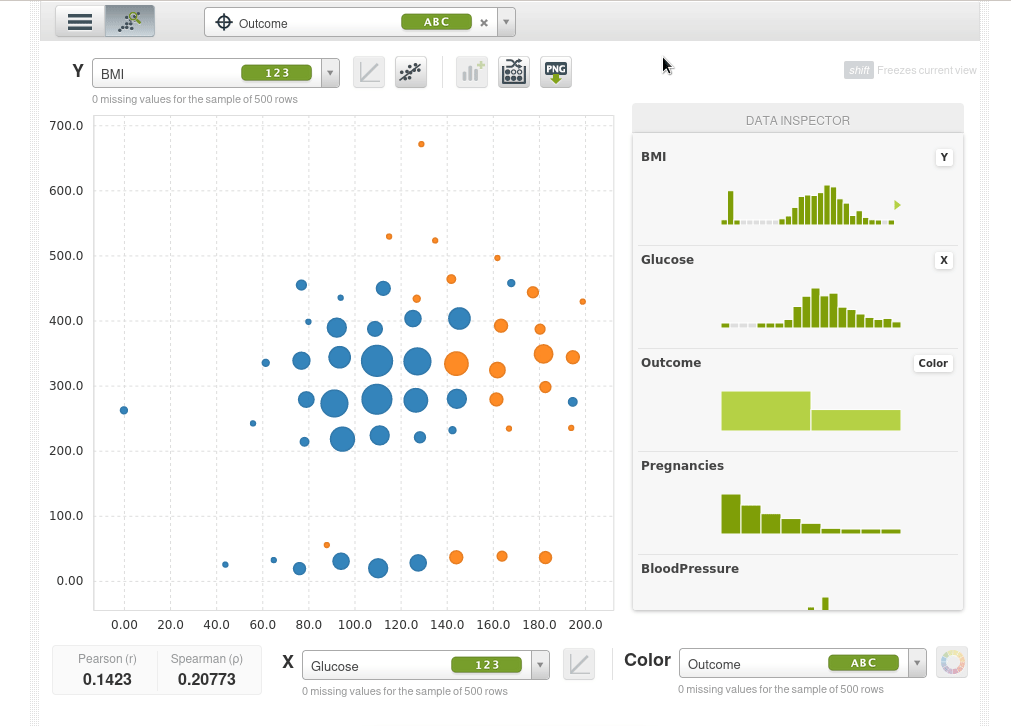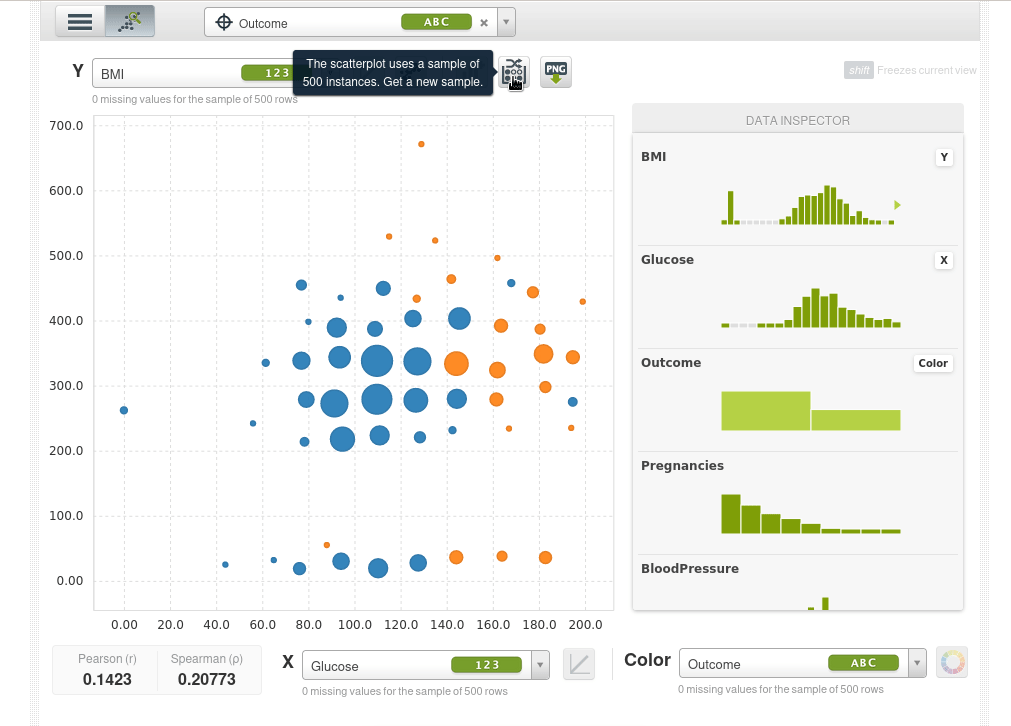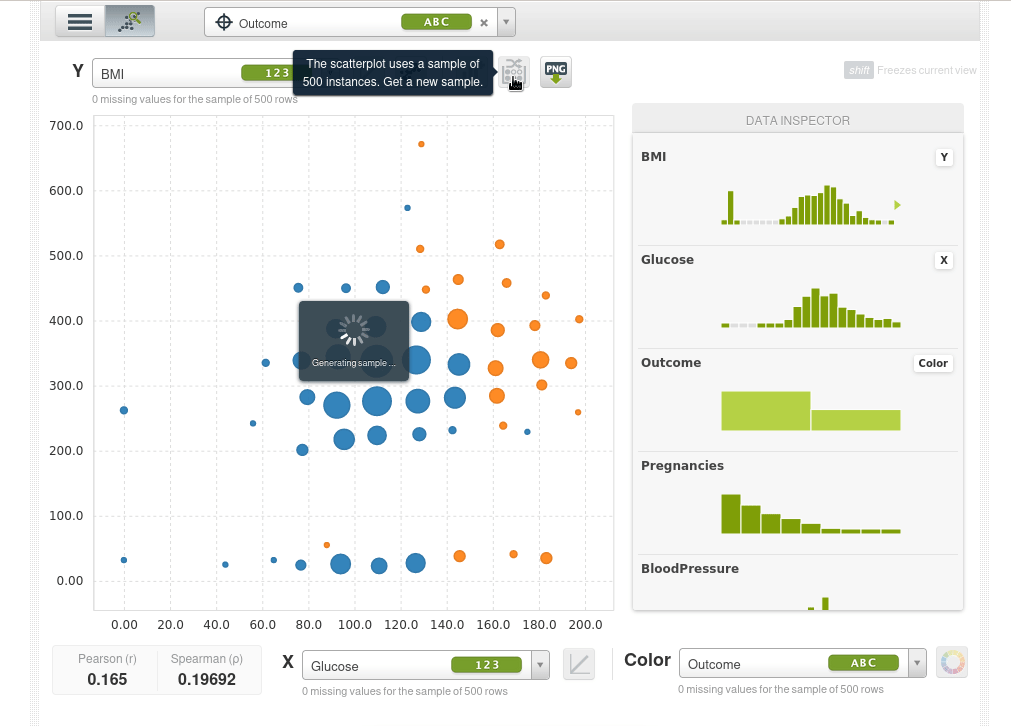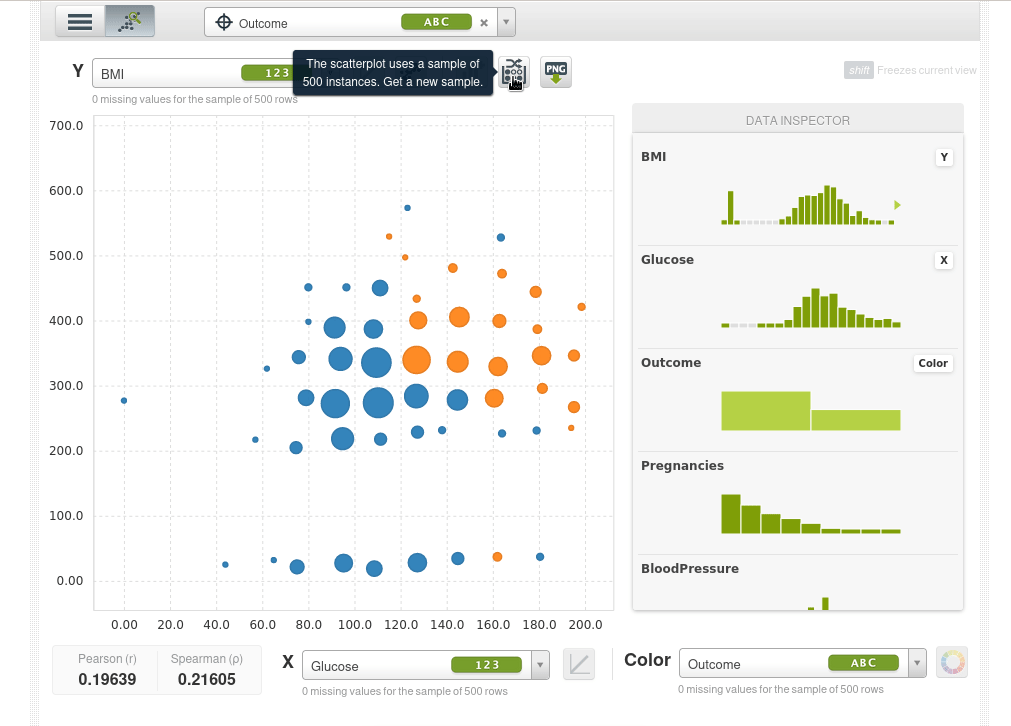
También podemos ampliar un área de la muestra (si hacemos simplemente clic sobre al área de muestra vuelve a empequeñecerse):
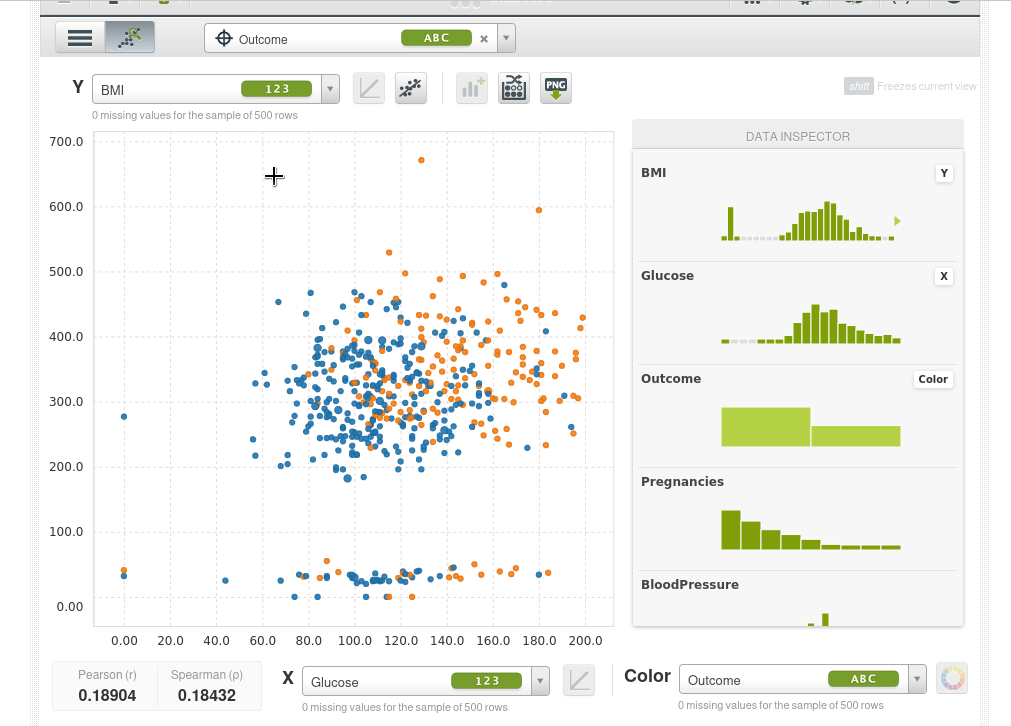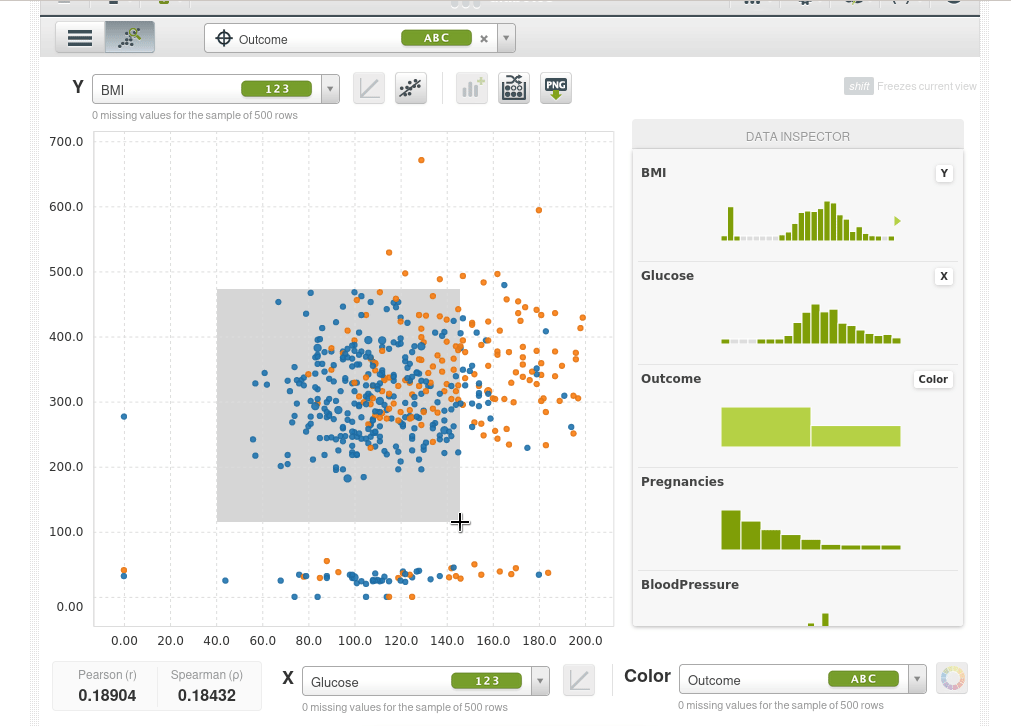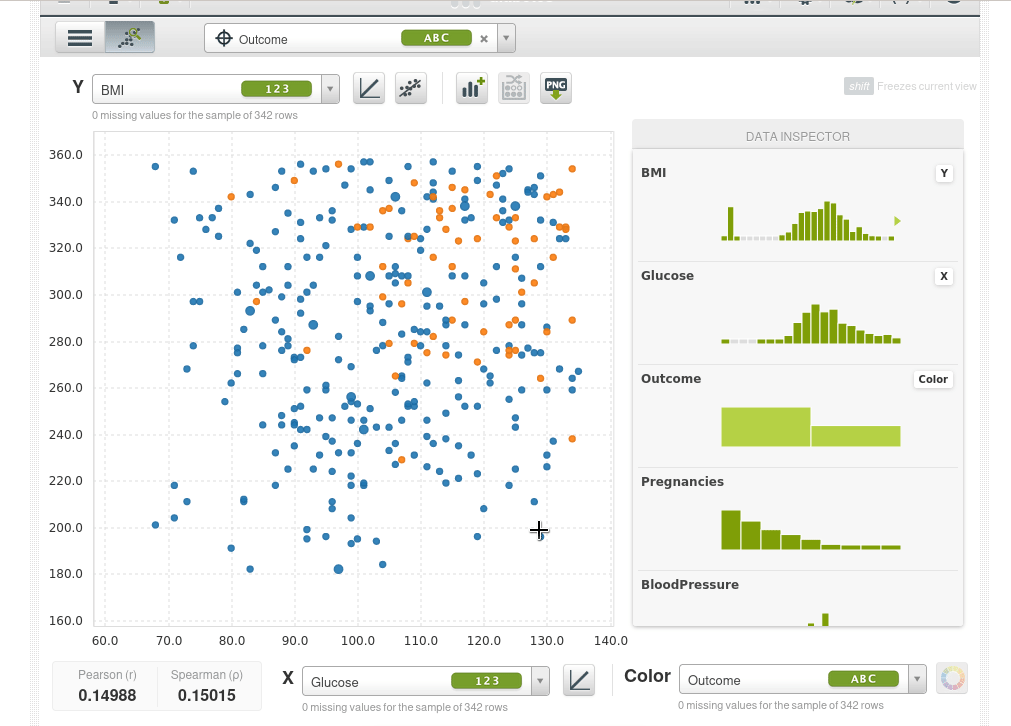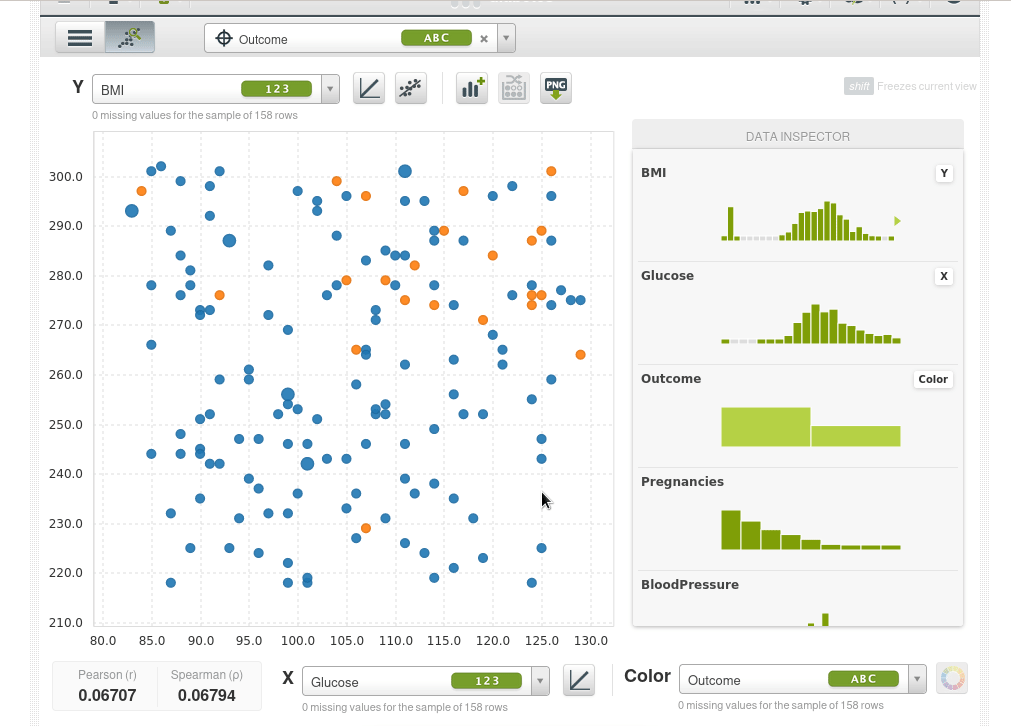
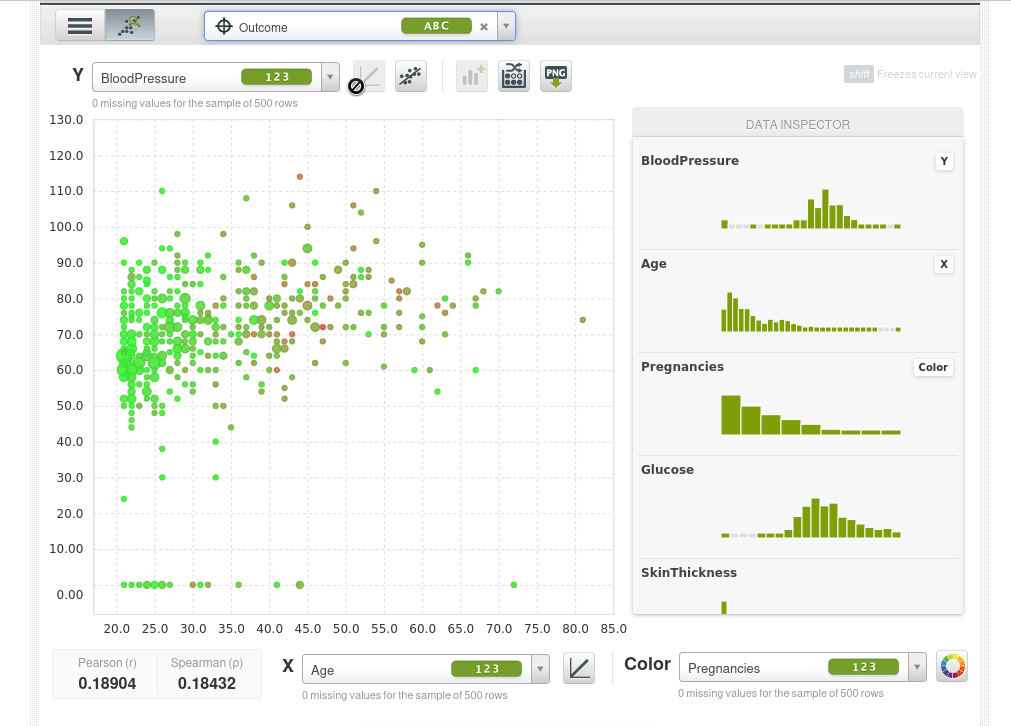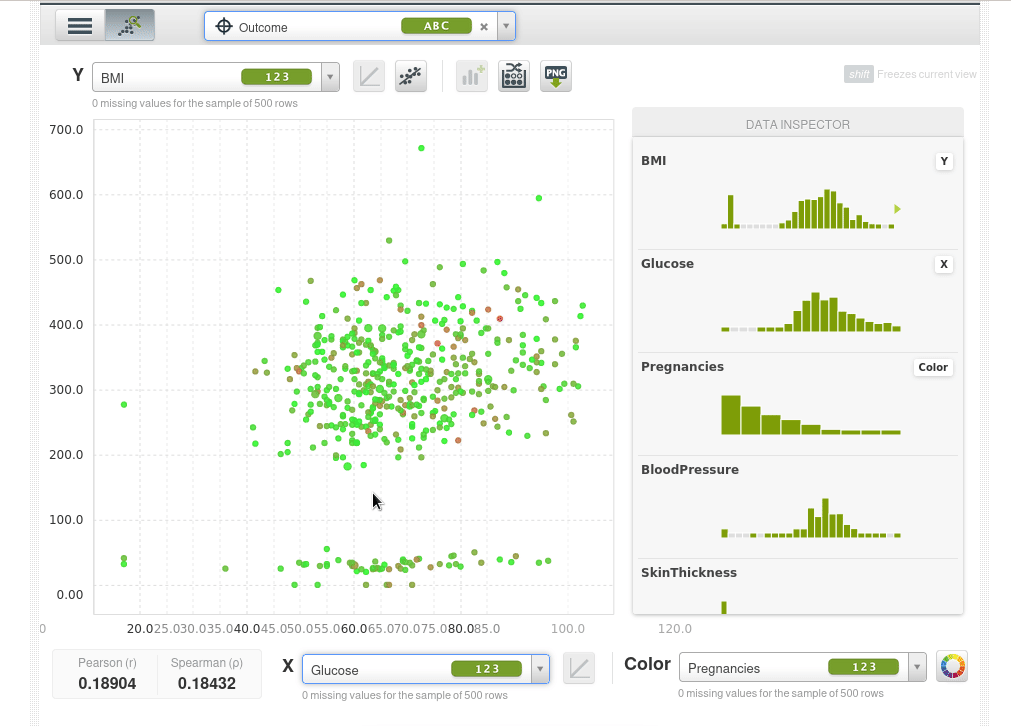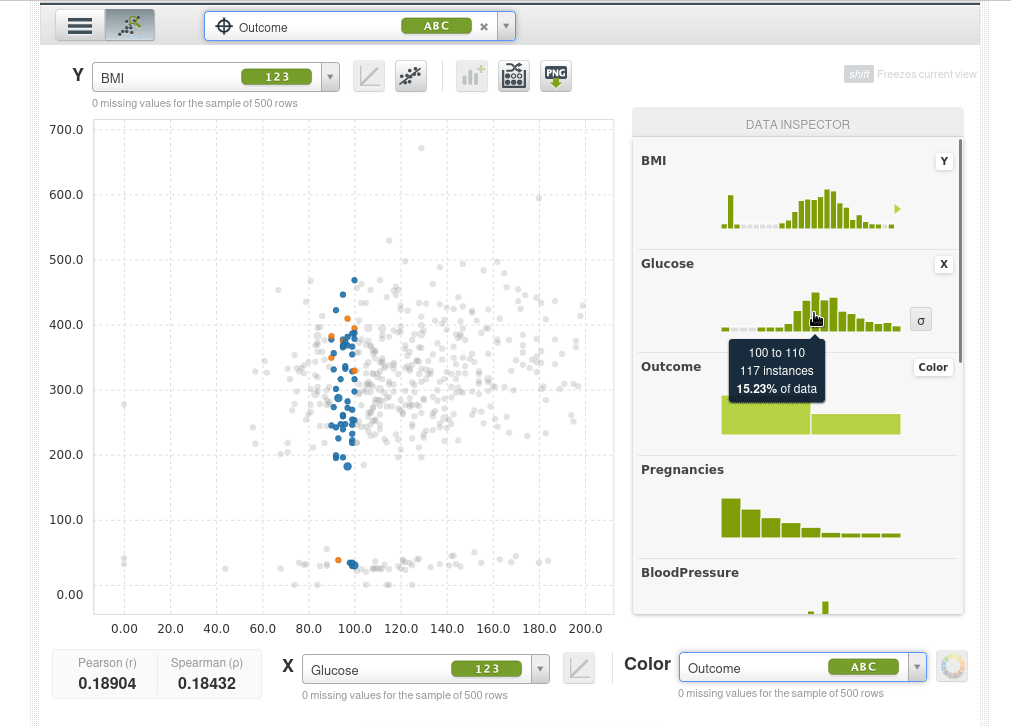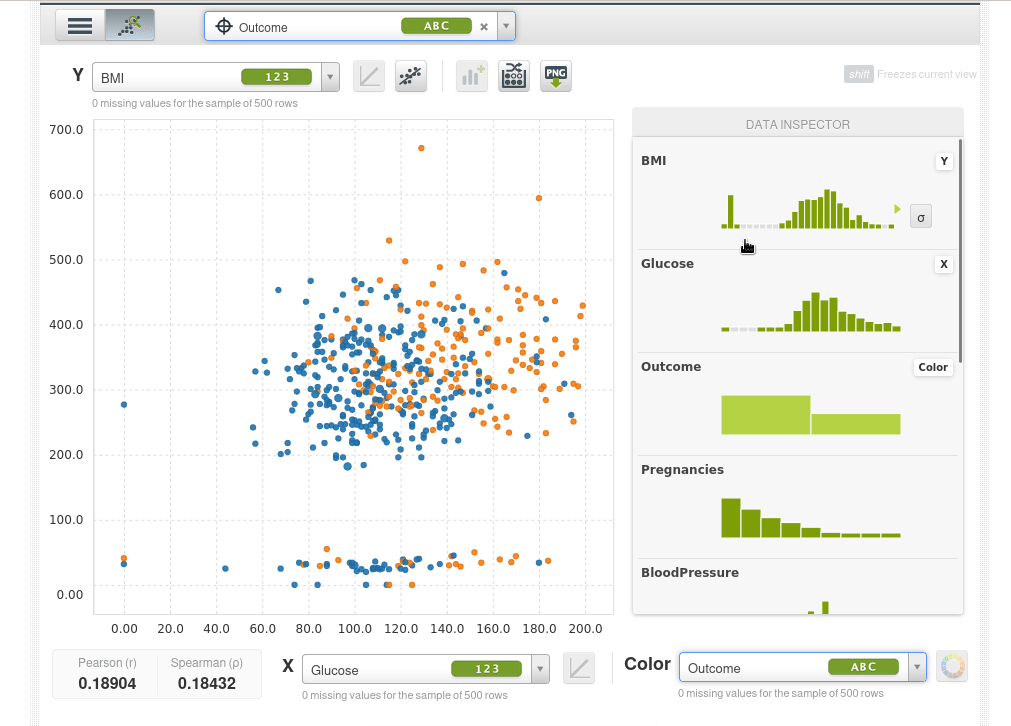
Incluso puedes ajustar una regresión lineal simple.
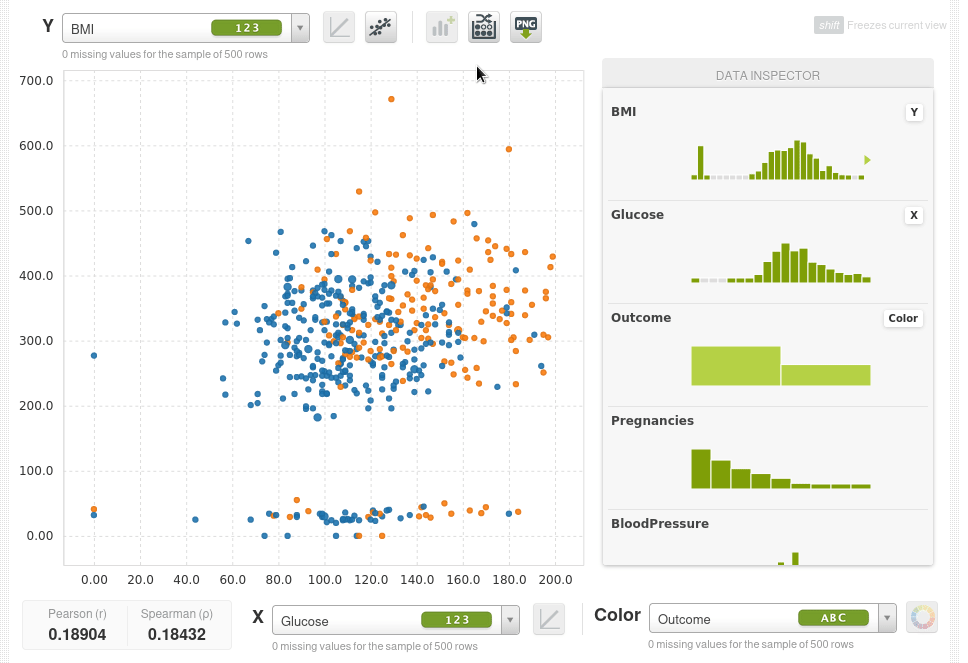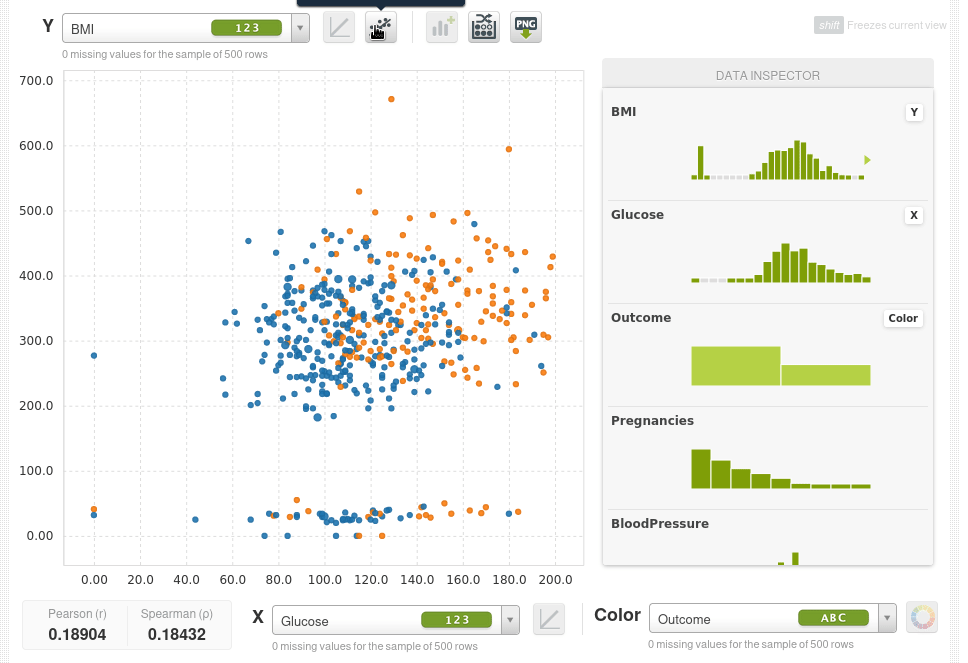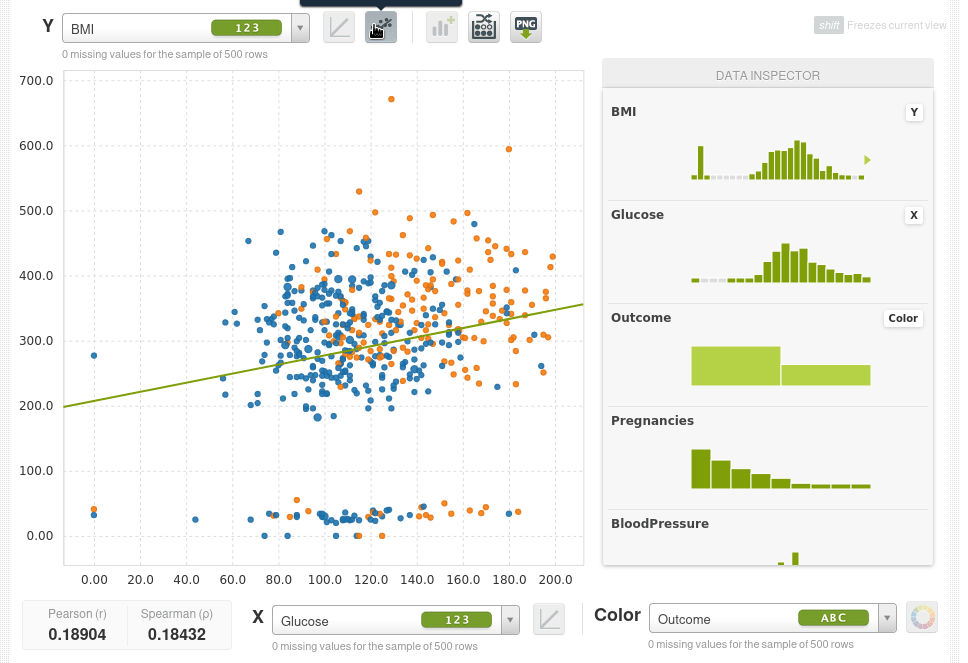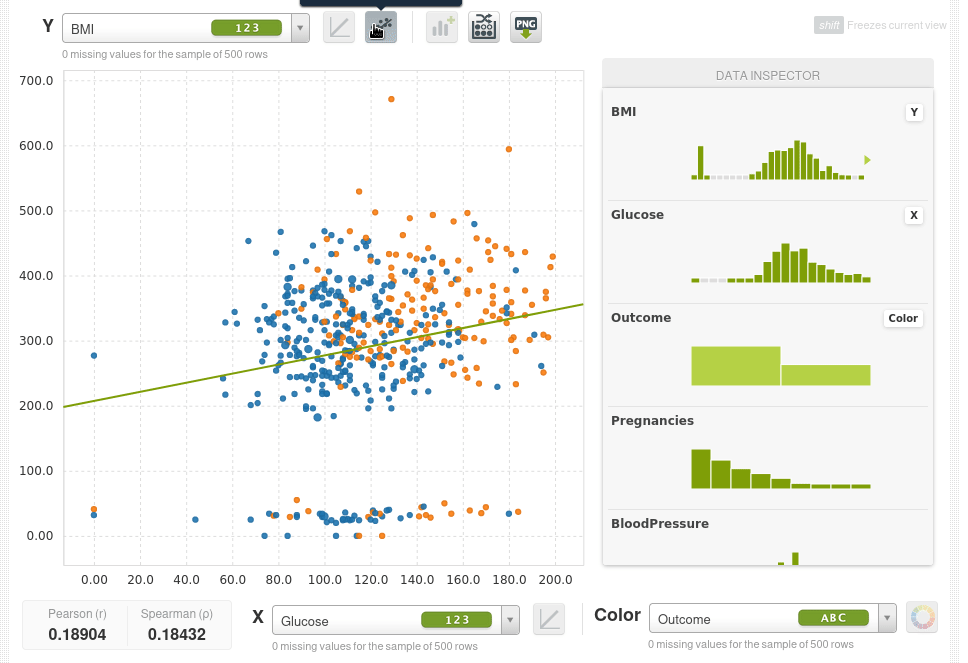
En la parte inferior también puedes ver los coeficientes de correlación de Pearson y de Spearman.
Esta también es una herramienta muy poderosa para detectar anomalías, por ejemplo visualizamos la presión arterial en ambos ejes, podemos observar casos con presión arterial de cero, estos probablemente serán pacientes que no han registrado esta información (con un campo vacío, NULL o NaN etc) y en su lugar se introdujo un cero como valor ausente. Pero esto podría sesgar los datos, por lo que puedes limpiar estos datos, configurar y eliminar estos ceros e ingresar valores faltantes reales.
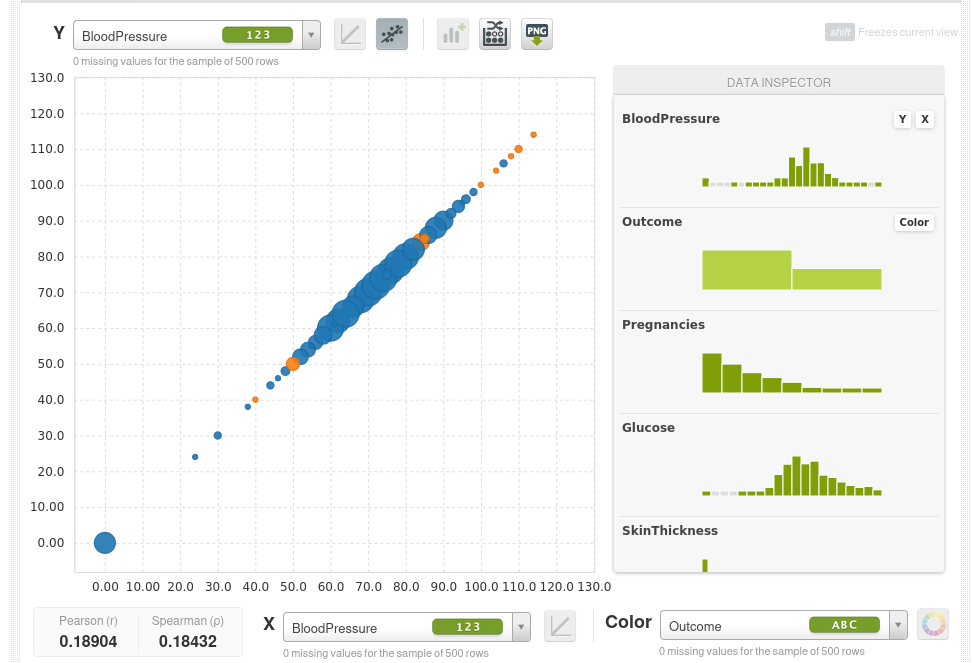
Esto también sucede con la insulina.
10. Detector de anomalías
El detector de anomalías de BigML es una herramienta diseñada para identificar datos inusuales o atípicos en un conjunto de datos. Estas anomalías pueden ser indicativas de errores, eventos raros o patrones interesantes que merecen una atención especial.
El detector de anomalías de BigML utiliza técnicas de aprendizaje no supervisado para analizar un conjunto de datos y encontrar patrones que difieren significativamente de lo que se considera normal. BigML emplea un enfoque basado en árboles de decisiones llamado “Isolation Forest” para detectar estas anomalías. Este enfoque es efectivo porque, en lugar de intentar perfilar la distribución normal de los datos, se enfoca en aislar las anomalías.
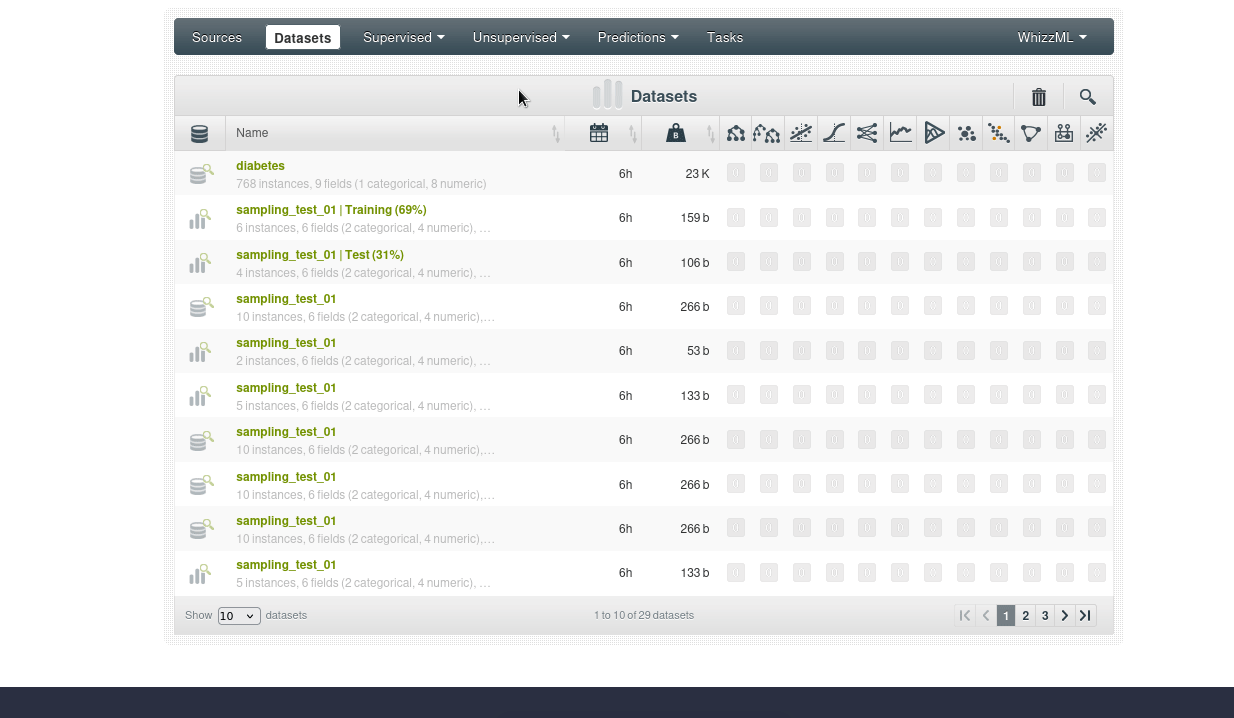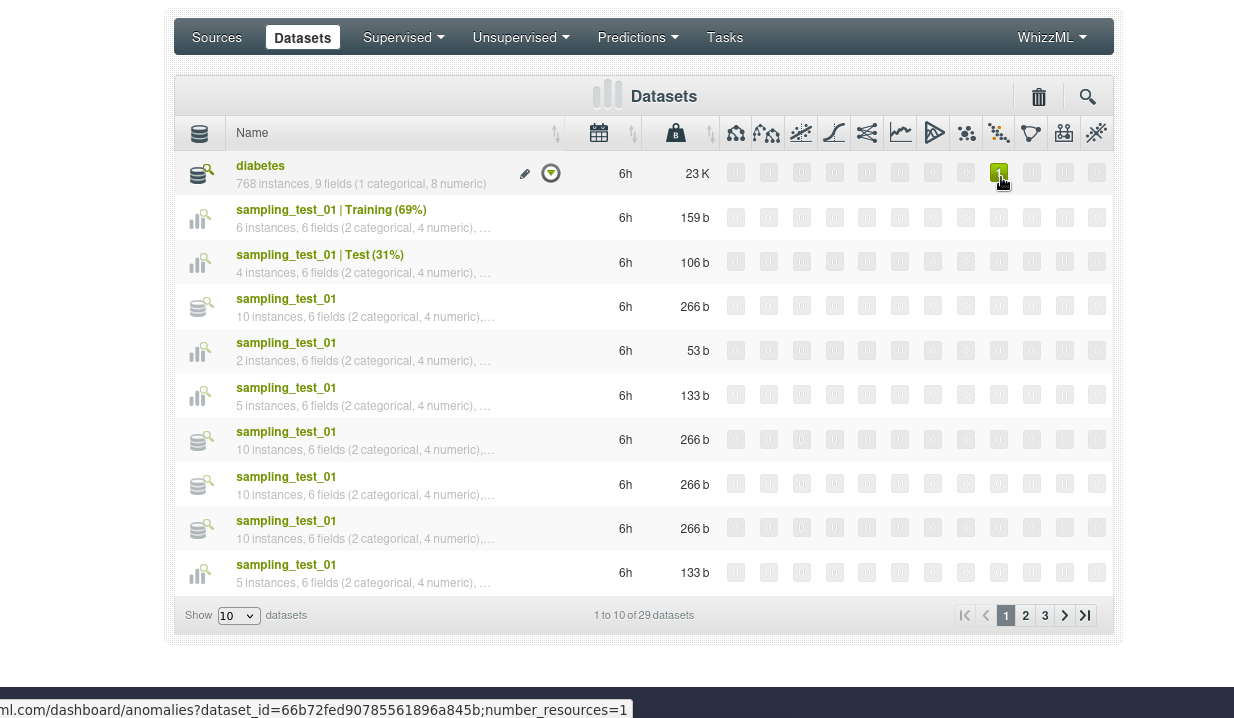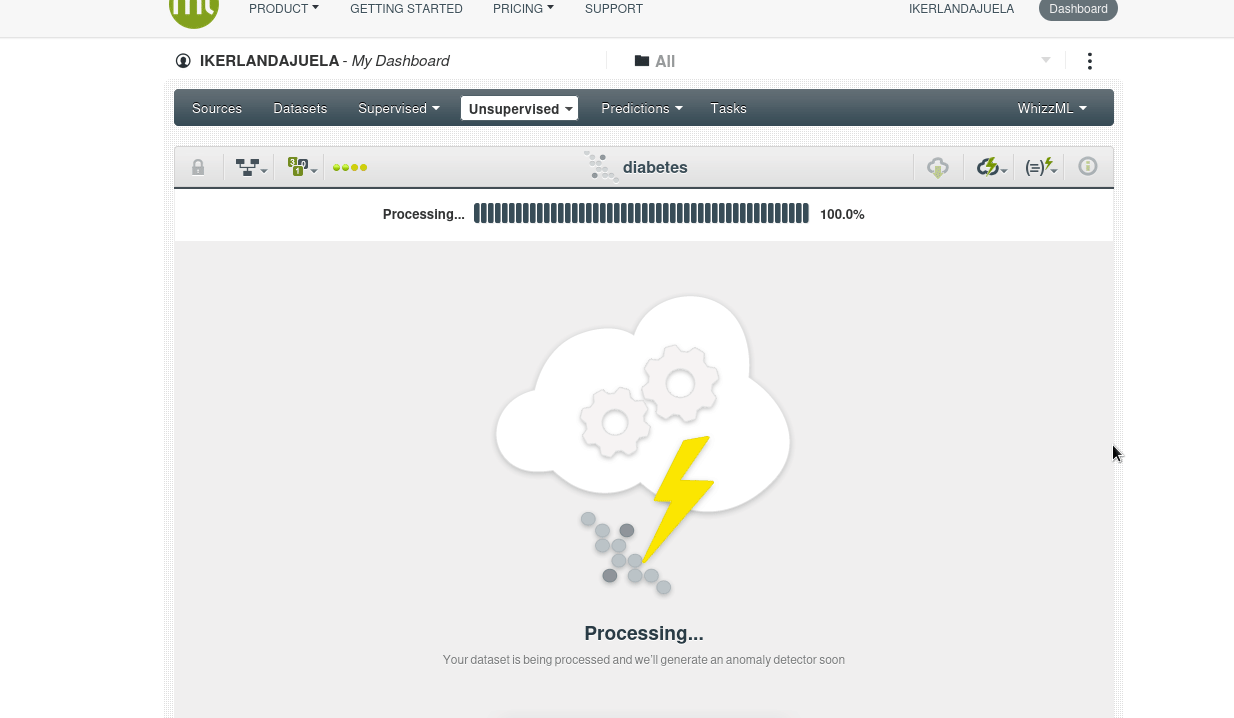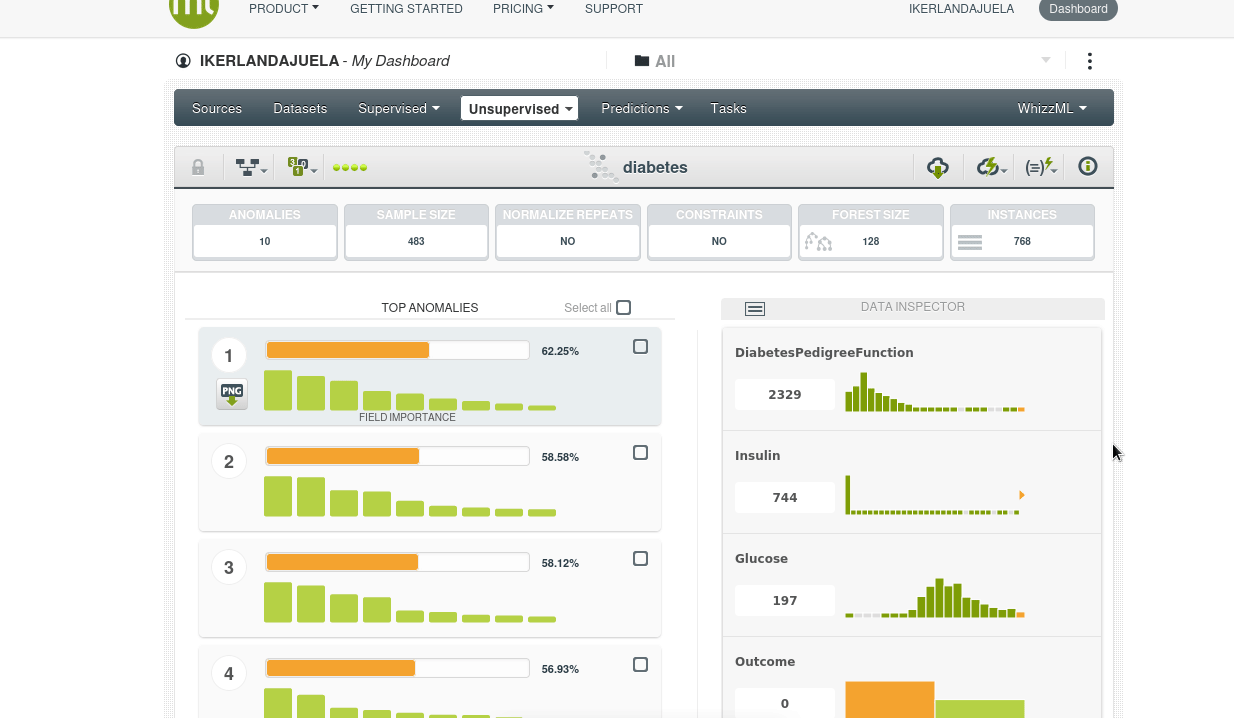
El resultado arroja instancias que se han detectado como anómalas (seguramente el conjunto de valores de esa instancia no es una combinación usual).
Cada instancia (fila) en el conjunto de datos se evalúa y se le asigna una “anomaly score” (puntuación de anomalía) que indica cuán atípica es. Esta puntuación generalmente varía entre 0 (no anómala) y 100 (muy anómala).
Puedes establecer un umbral para decidir qué puntuaciones se consideran anomalías.
Por ejemplo establece el umbral del IMC en 289, un índice de masa corporal (IMC o BMI, por sus siglas en inglés) de 289 no es posible ni realista para un ser humano. El IMC se calcula utilizando la fórmula: IMC = peso_kg / (altura_m)^2. Para ilustrar, un IMC de 289 significaría que una persona de 1.70 metros de altura tendría que pesar más de 835 kilogramos, se considera obesidad 30 o más de IMC.
Vamos a calificar todos los puntos de datos en el conjunto de datos original usando lo que se llama puntuación de anomalías por lotes, por lo que tomará todos los datos y agregará un nuevo campo con la puntuación de anomalía y el resultado será un nuevo conjunto de datos.
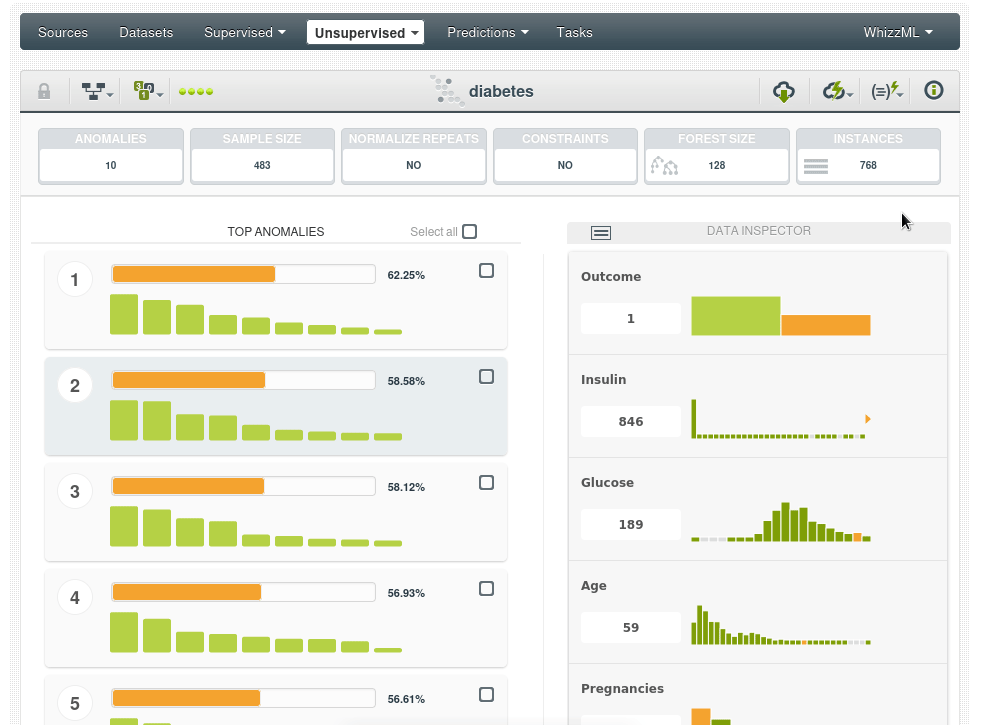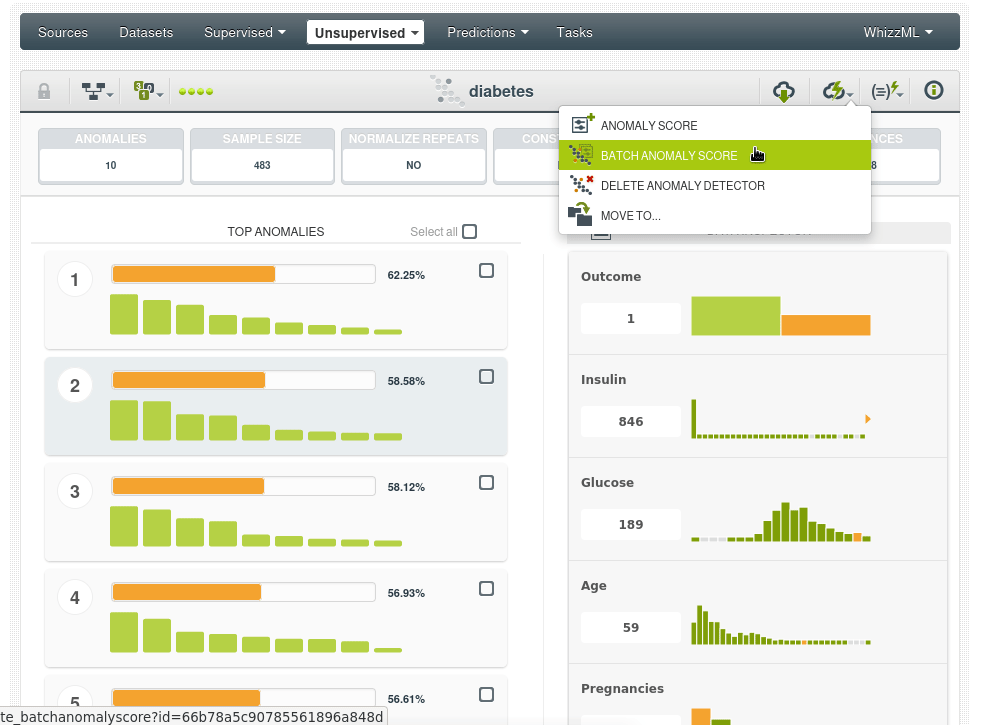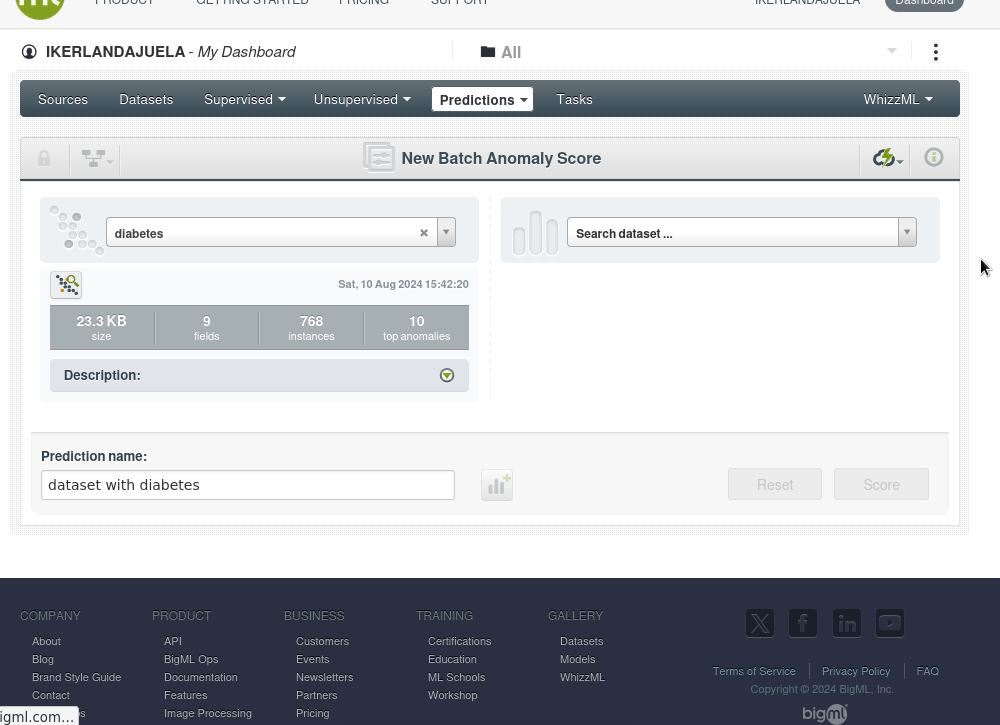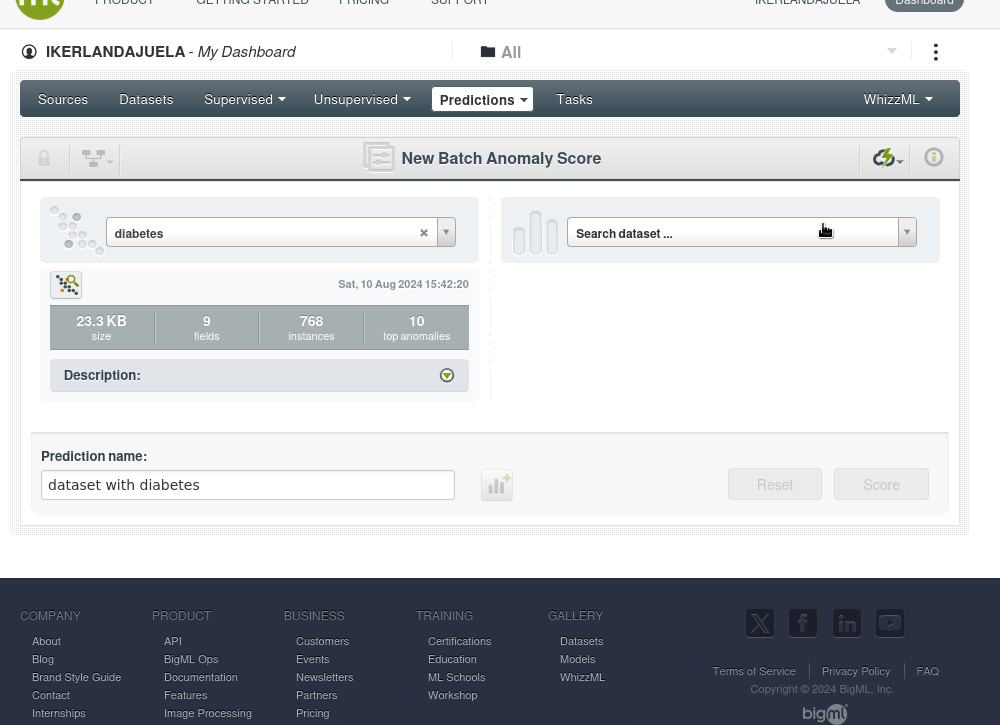
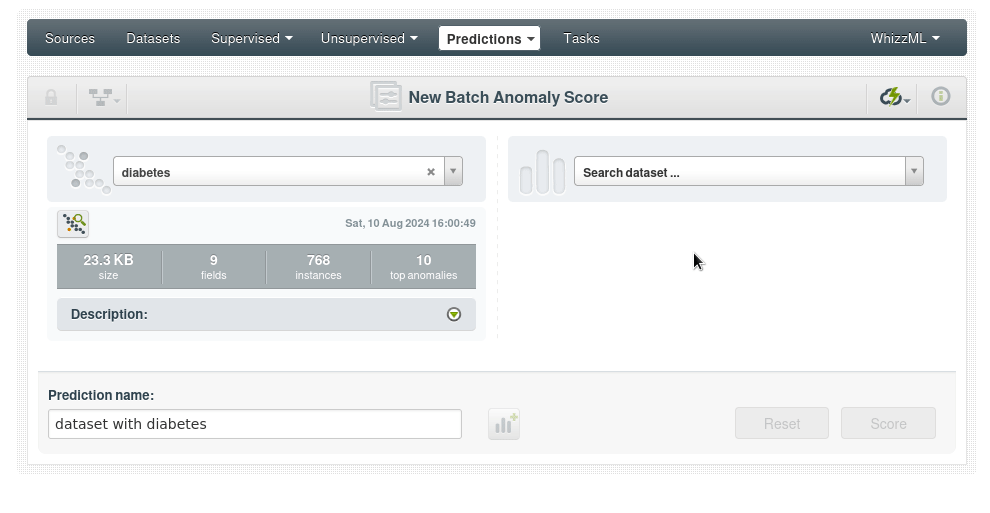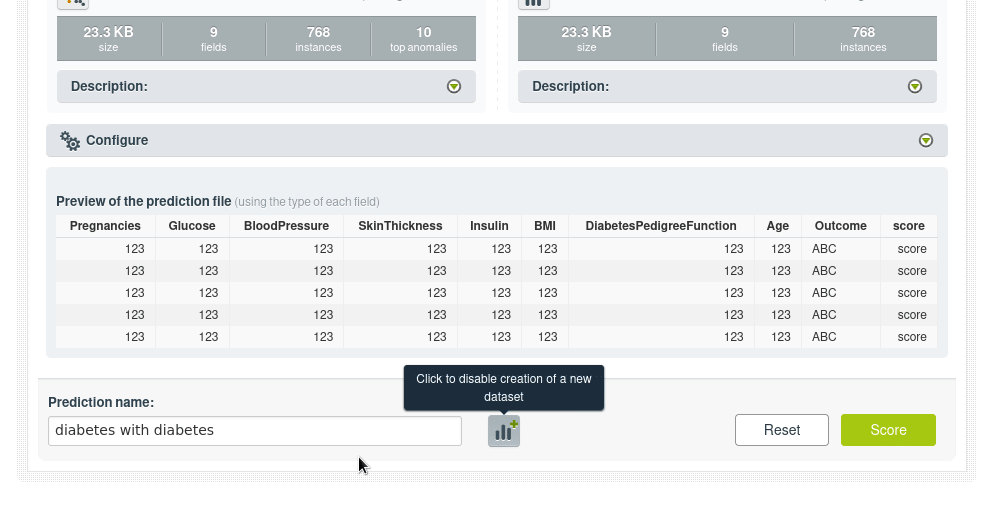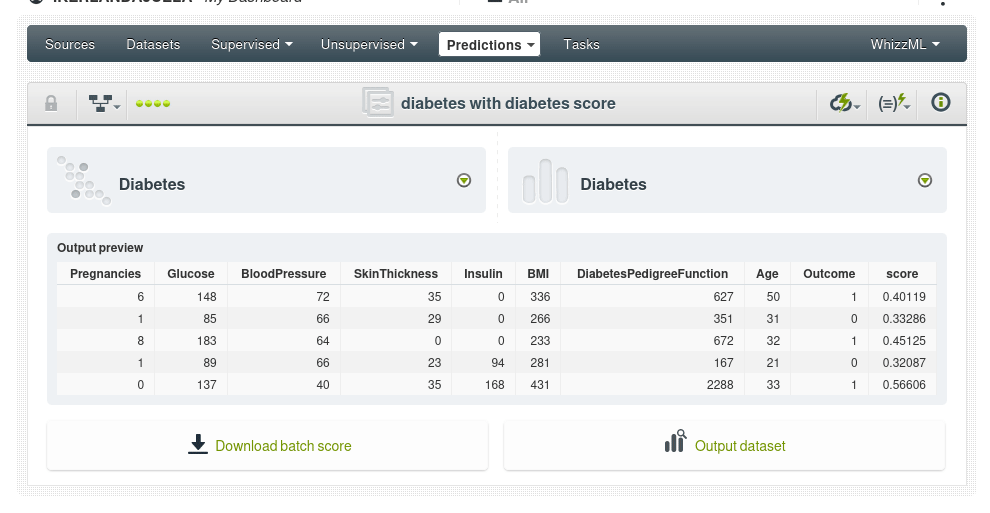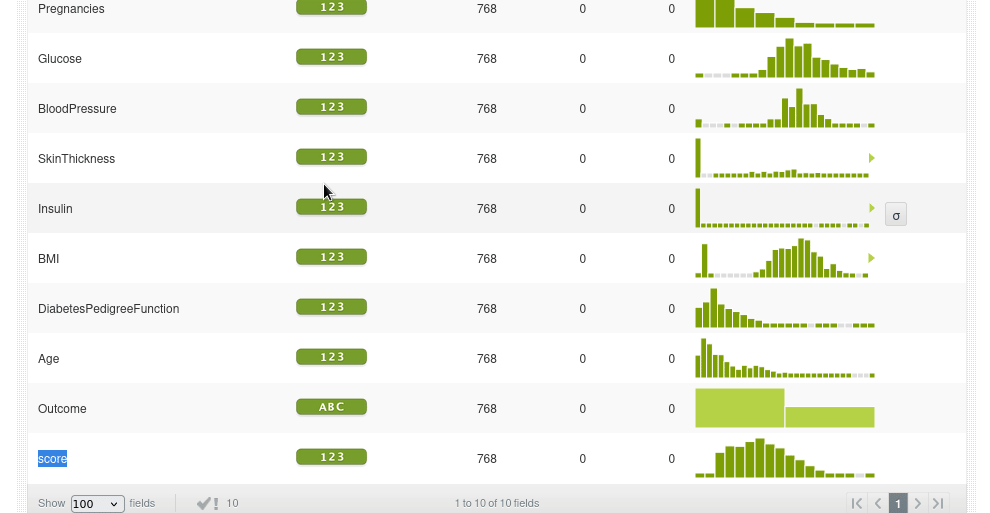
Nuevo dataset, ha aumentado su tamaño por el campo adicional pero sigue manteniendo el mismo número de instancias:
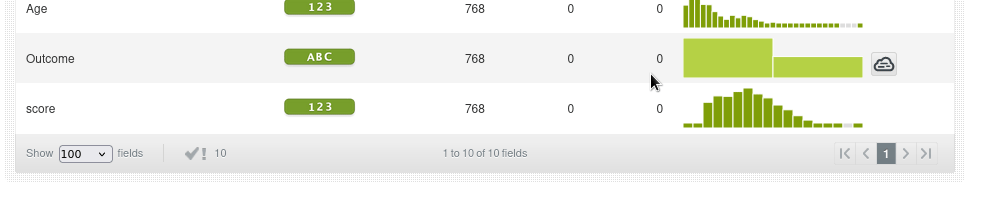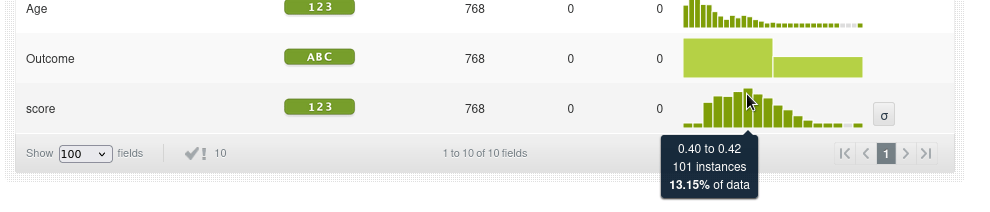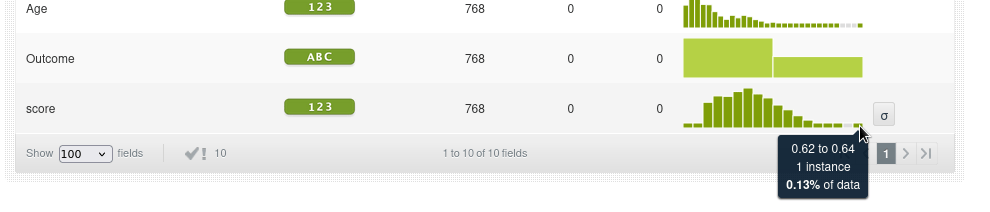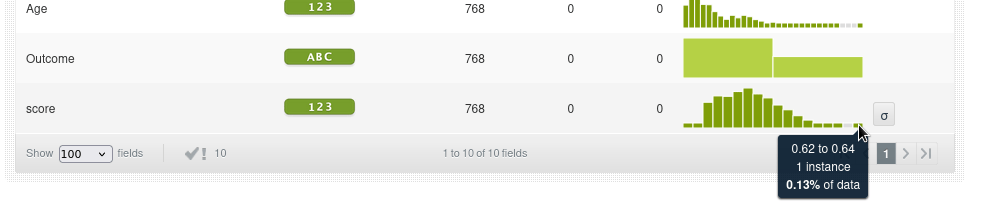
Vemos además que el score de anomalías más frecuente es de 0.40 a 0.42. Un score de 0.42 sugiere que la instancia no es completamente normal, pero tampoco es extremadamente anómala. Está en un punto intermedio. Por ejemplo las anomalías con un score alto de 0.62 a 0.64 sólo representa el 0.13% de los datos, es decir, una instancia.
Volvemos al diagrama de dispersión para analizar los scores:
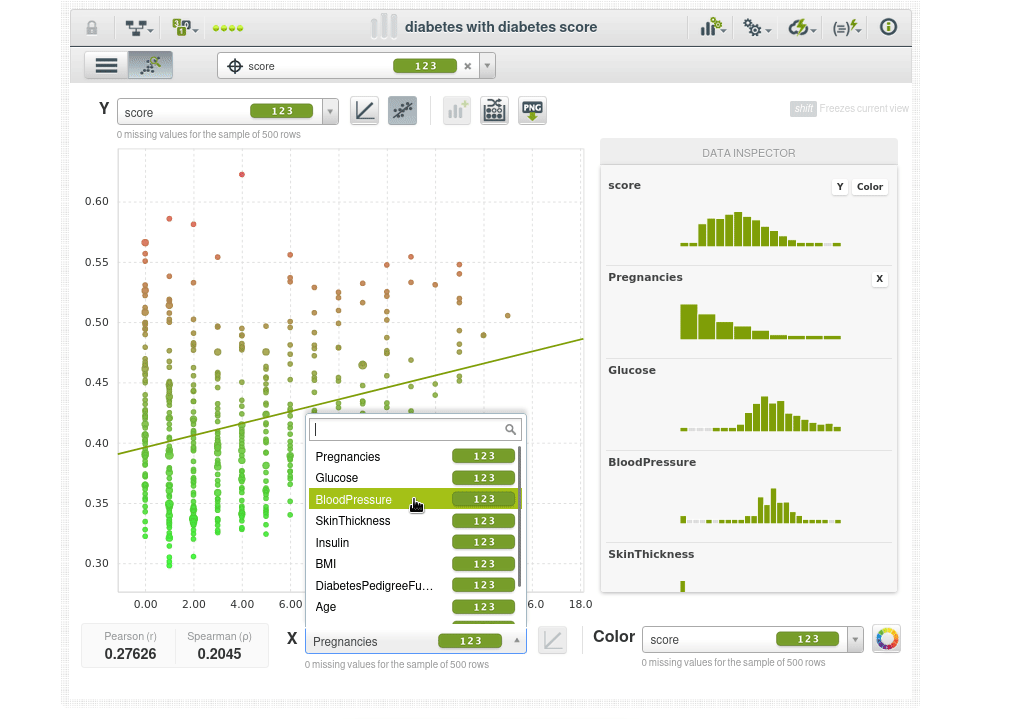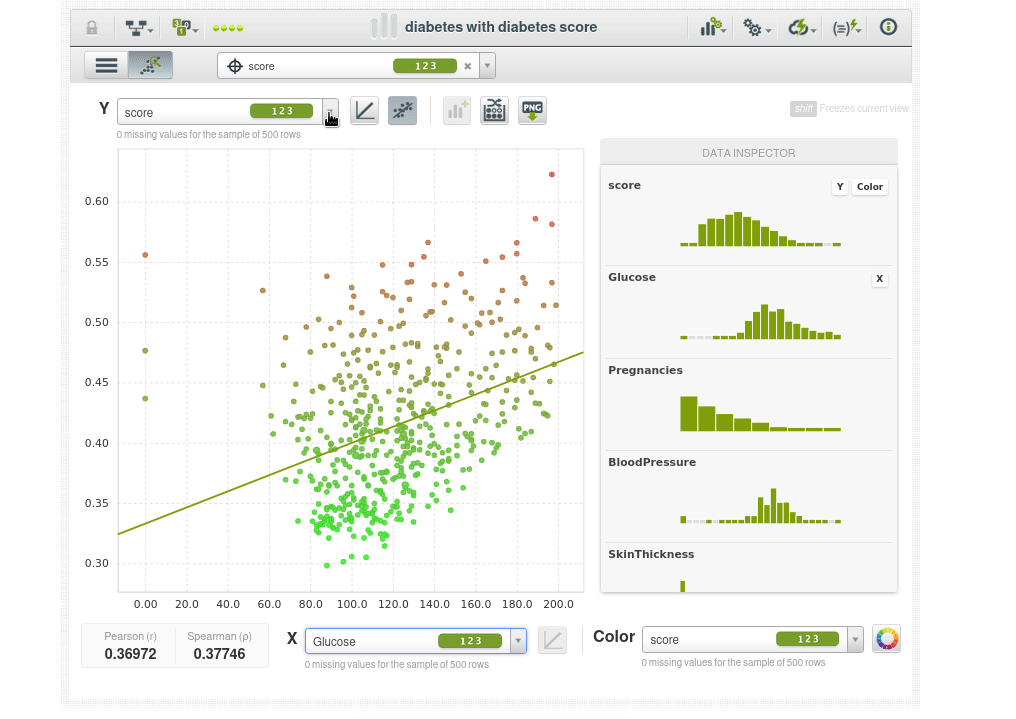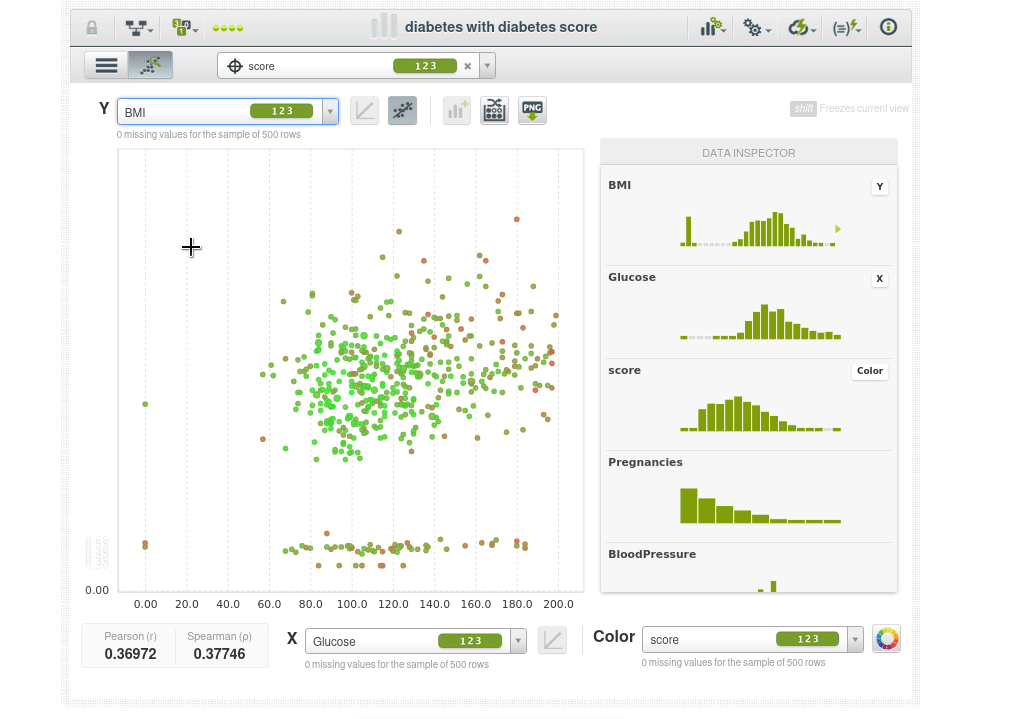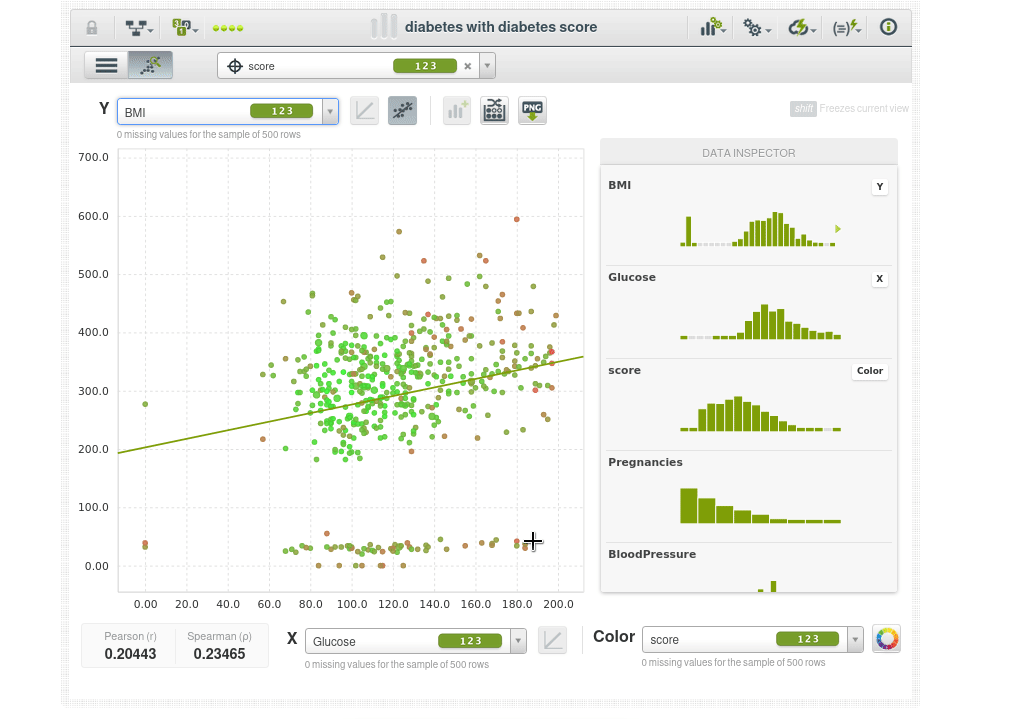
La coloración de los puntos es según la puntuación de anomalía, por lo que los puntos de color verde brillante tienen una puntuación de anomalía más baja, como se puede ver en el inspector de datos, el punto de datos verde brillante tiene una puntuación de 0.3X, y los puntos que son más rojos tienen una puntuación de anomalía más alta 0.5X.
Por ejemplo el paciente en la esquina superior derecha parece un dato atípico con 600 de IMC y 180 de glucosa (los niveles de glucosa en ayunas superiores a 126 mg/dL pueden ser indicativos de diabetes).
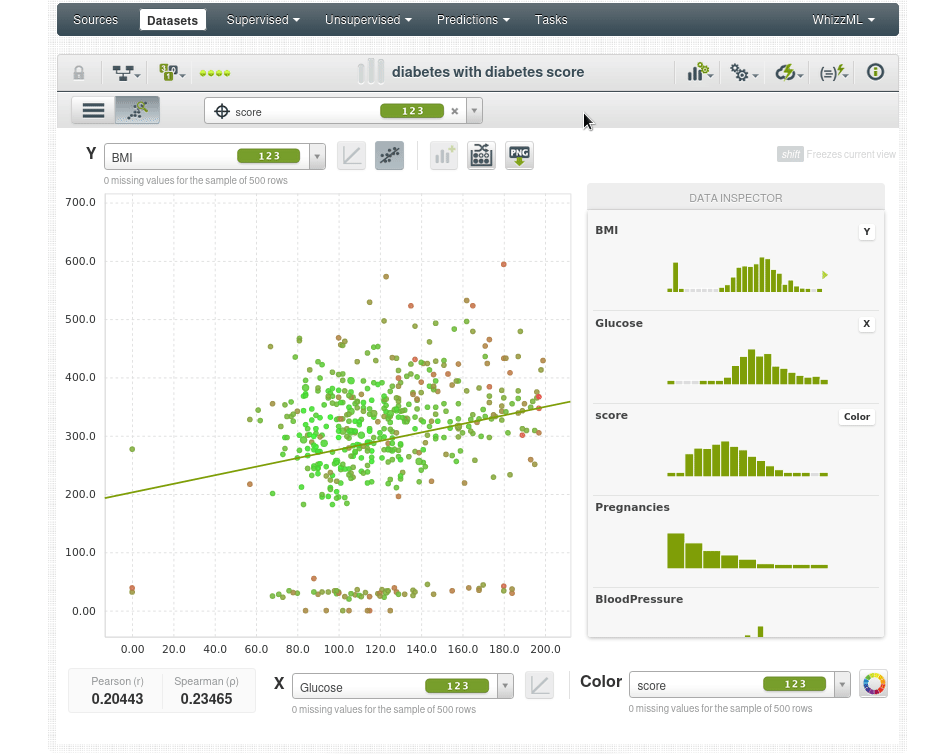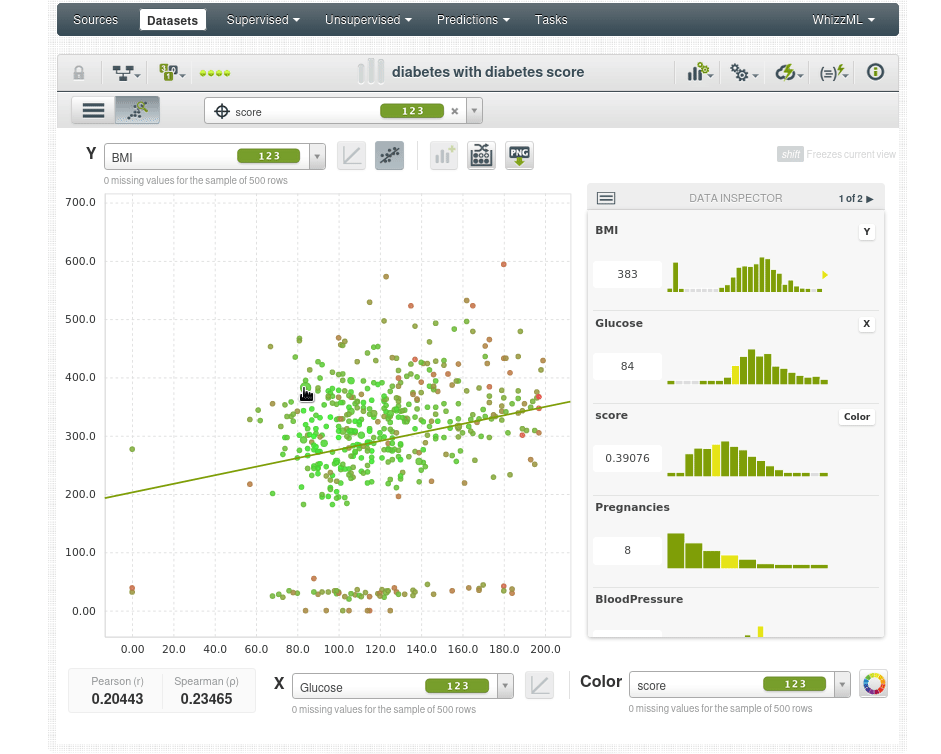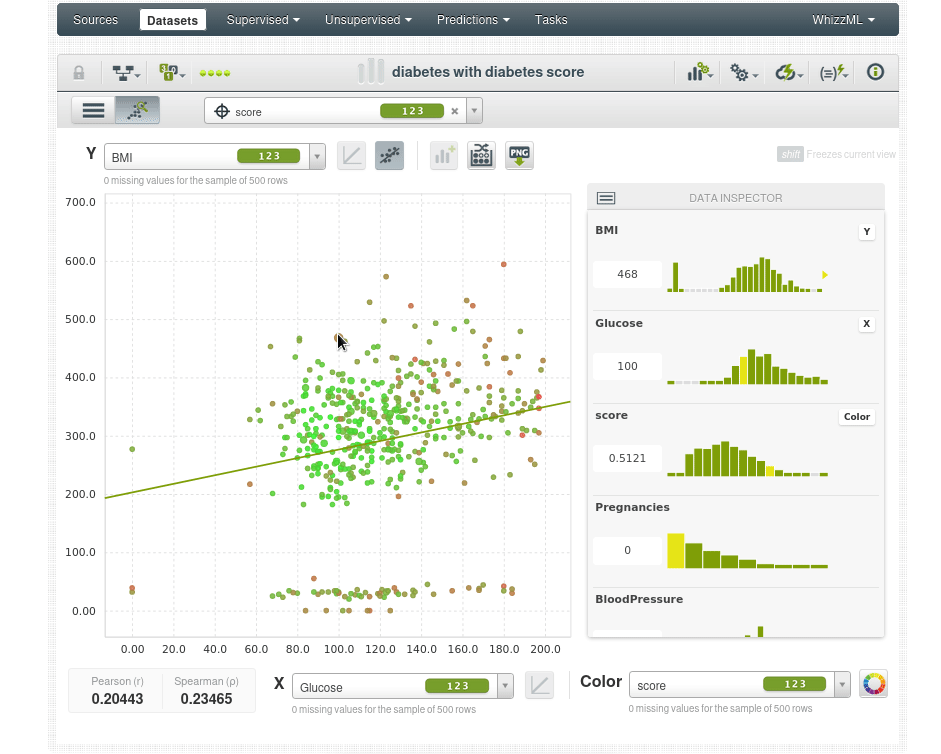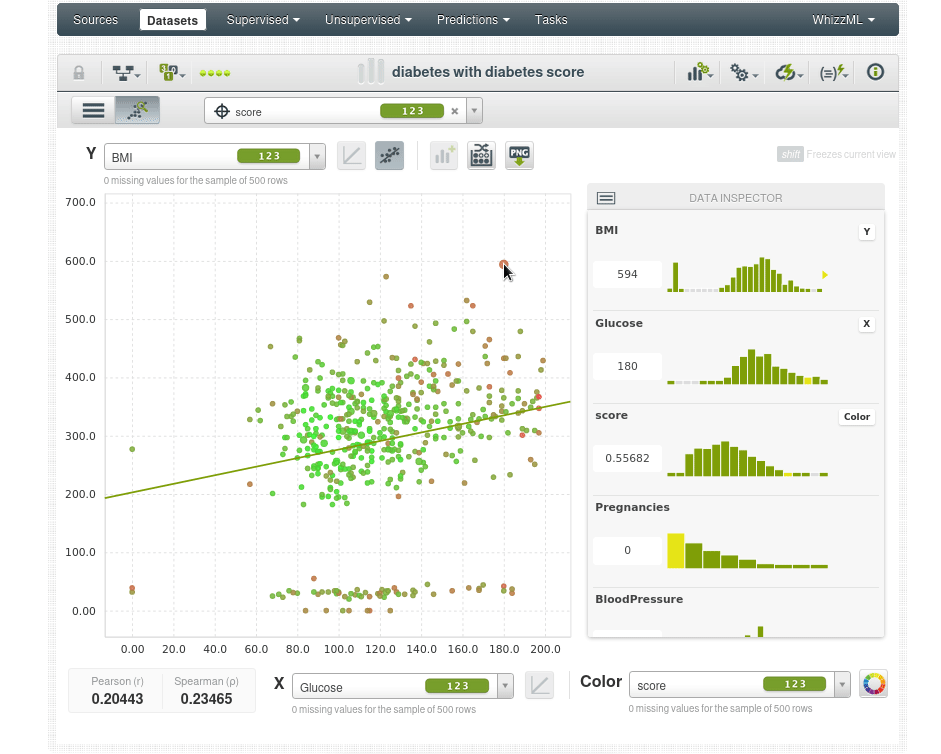
Podemos echar un vistazo entre la población “normal” en el centro de la nube de datos para buscar valores atípicos.
Por ejemplo vemos un caso anómalo en rojo (score de 0.62), a pesar de tener un IMC y una glucosa anormalmente altos no tiene diabetes:
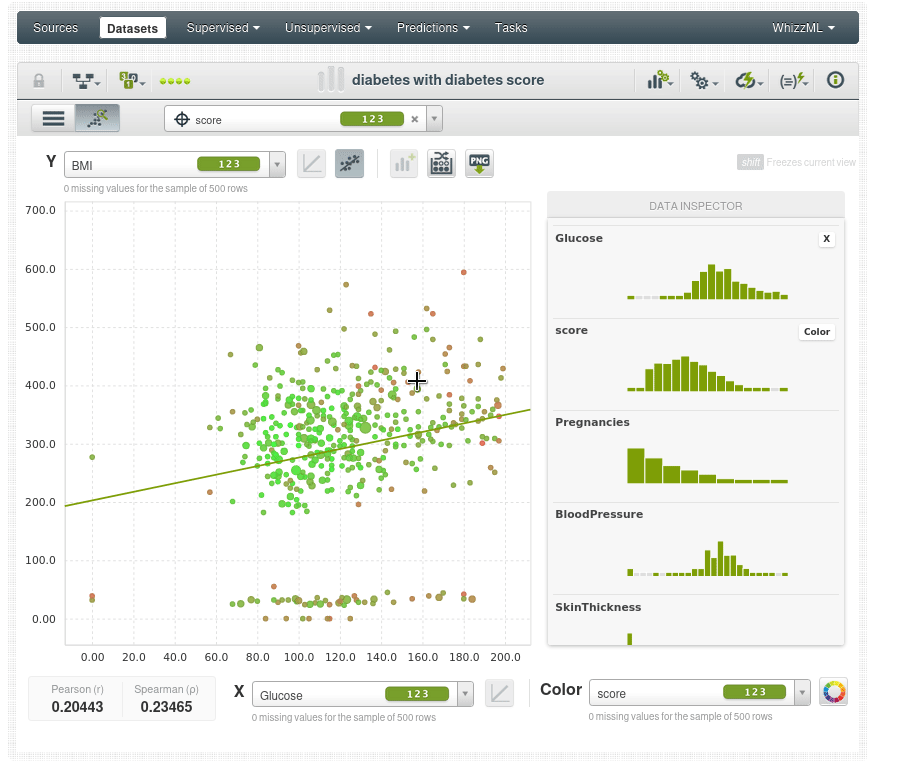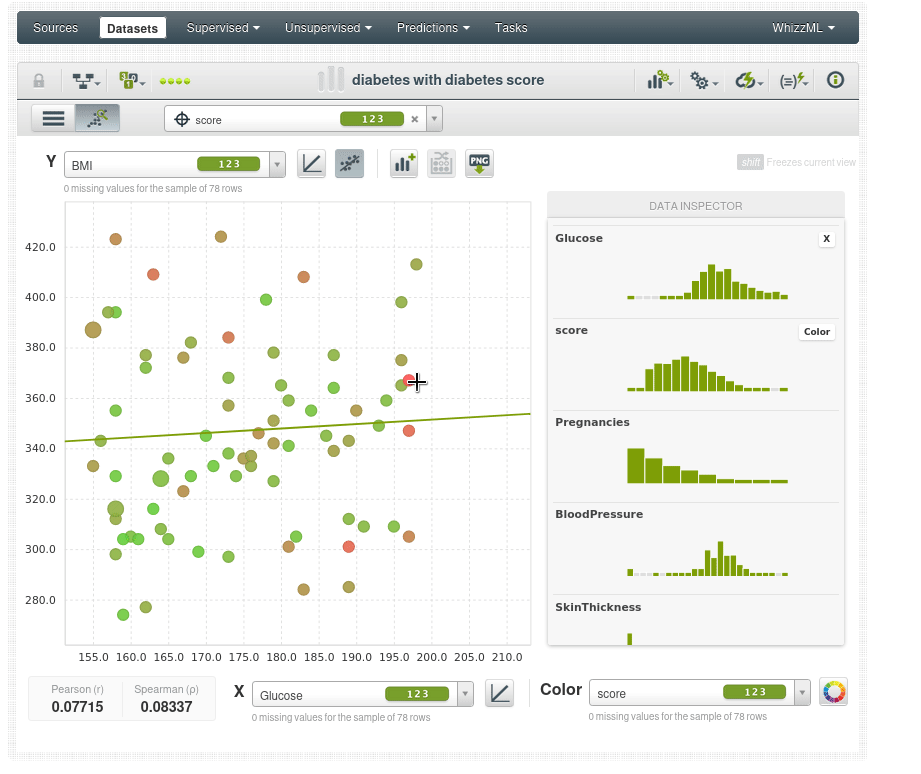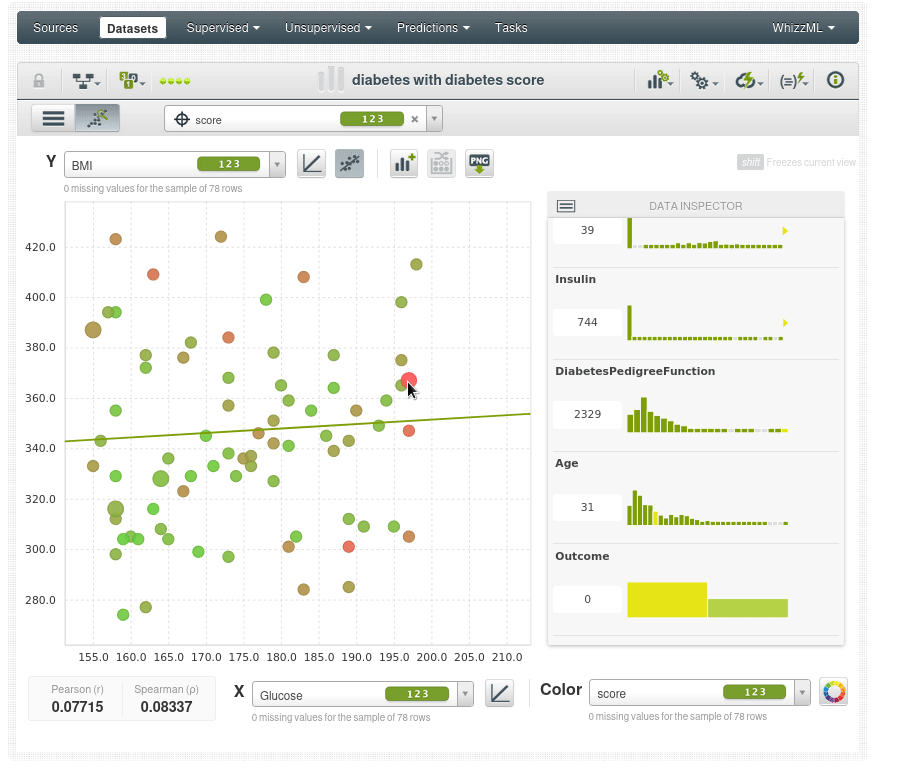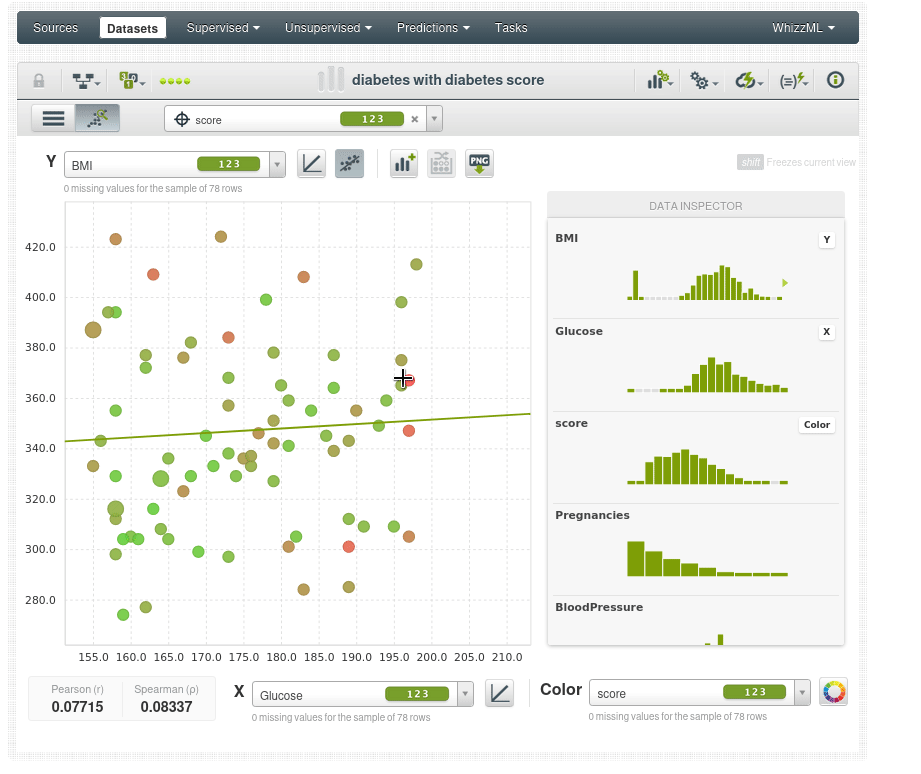
Esto podría ser un error en los datos, o podría ser la persona más afortunada del mundo. Pero si es la persona más afortunada del mundo no es adecuada para el modelo predictivo porqué el modelo necesita poder generalizarse y ese punto de datos no se generalizará muy bien. No todos podemos ser la persona más afortunada del mundo.
11. Características avanzadas
- Filtrado del dataset para crear nuevos conjuntos de datos.
- Ingeniería de características (feature engineering), donde vamos a crear nuevos campos en el dataset usando los campos existentes.
Ahora usamos este dataset de Kaggle Lending Club Loan Dataset, este conjunto de datos representa miles de préstamos realizados a través de la plataforma Lending Club, que es una plataforma que permite a los individuos prestar a otros individuos.
11.1. Filtros
El campo loan_status (estado del préstamo) indica en que estado se encuentra el préstamo y puede contener una serie de valores:
- “Charged Off”: Anulado. El préstamo se ha dado por incobrable, es decir, el prestamista ha decidido que el préstamo no será recuperado y lo considera perdido.
- “Current”: Vigente.
- “Default”: El préstamo ha incumplido sus términos, generalmente porque el prestatario ha dejado de hacer pagos y el préstamo se ha considerado en mora o no recuperable.
- “Fully Paid”: El préstamo ha sido pagado en su totalidad.
- “In Grace”: Está en periodo de gracia.
- “Late (16-30 days)”: Retraso de 16 a 30 días.
- “Late (31-120 days)”.
Queremos filtrar este campo para obtener un nuevo conjunto de datos sólo con los prestamos abiertos (current, in grace, late), de manera similar crearemos otro conjunto de datos con los prestamos cerrados (charged off, default, fully paid). Podemos usar ambos modelos para predecir como acabará un préstamo abierto, un pago incumplido o anulado es un mal préstamo en contraste con una completamente pagado. **Queremos diseñar una nueva característica (feature engineering) que en lugar de tener las 3 clases de cerrado cree una medida de malo (charged off, default) o bueno (fully paid)

Estos son los pasos que vamos a seguir. Primero vamos a la opción de filtrado:
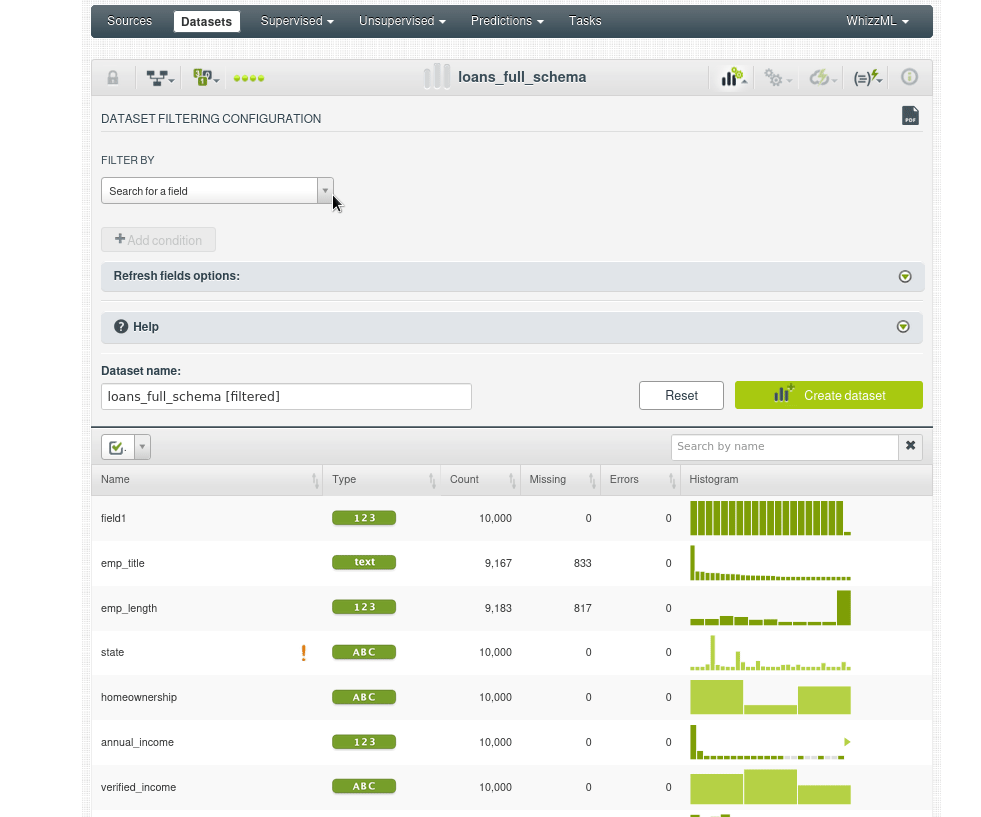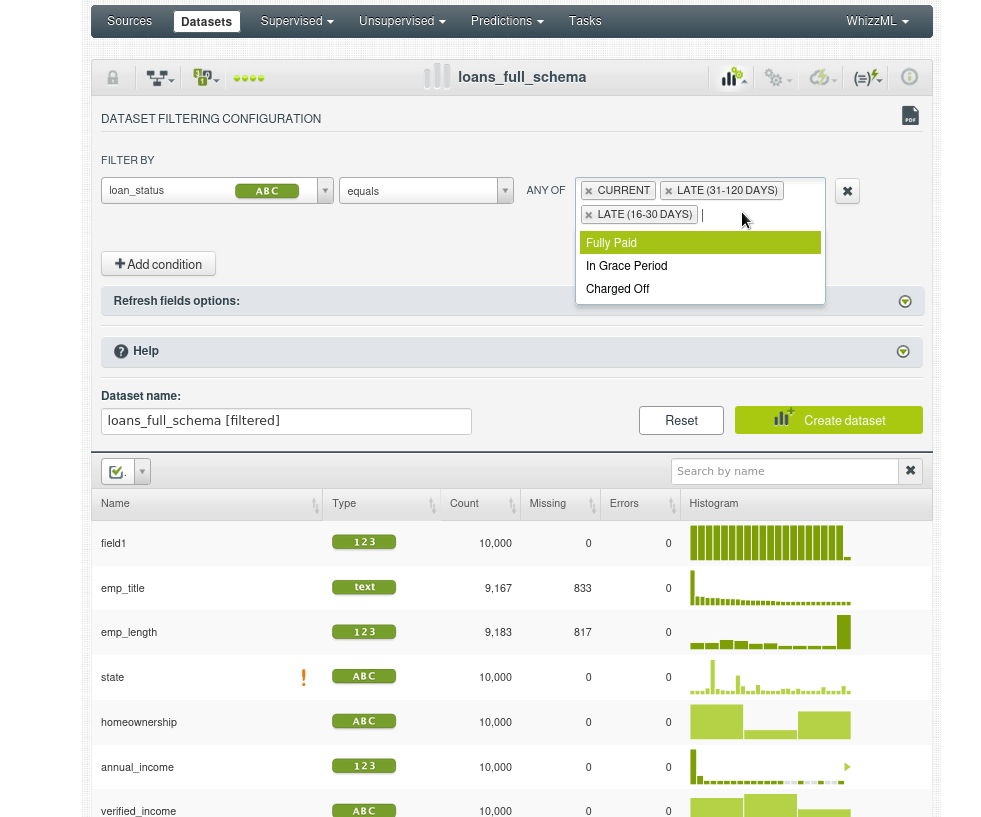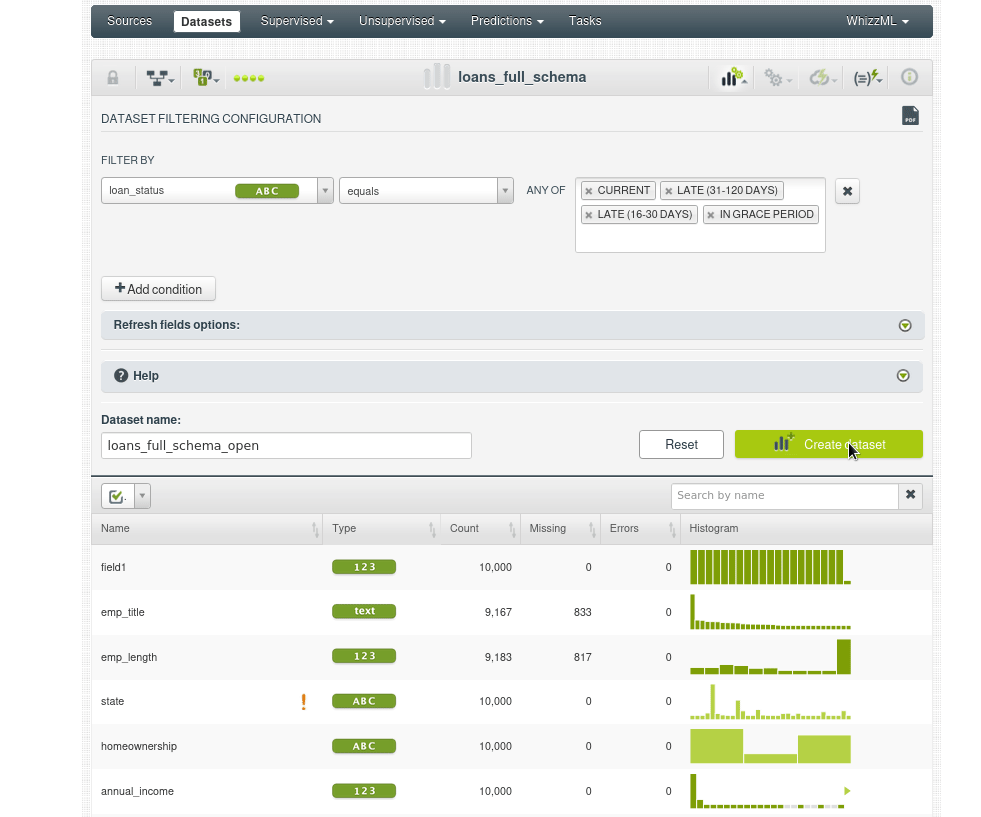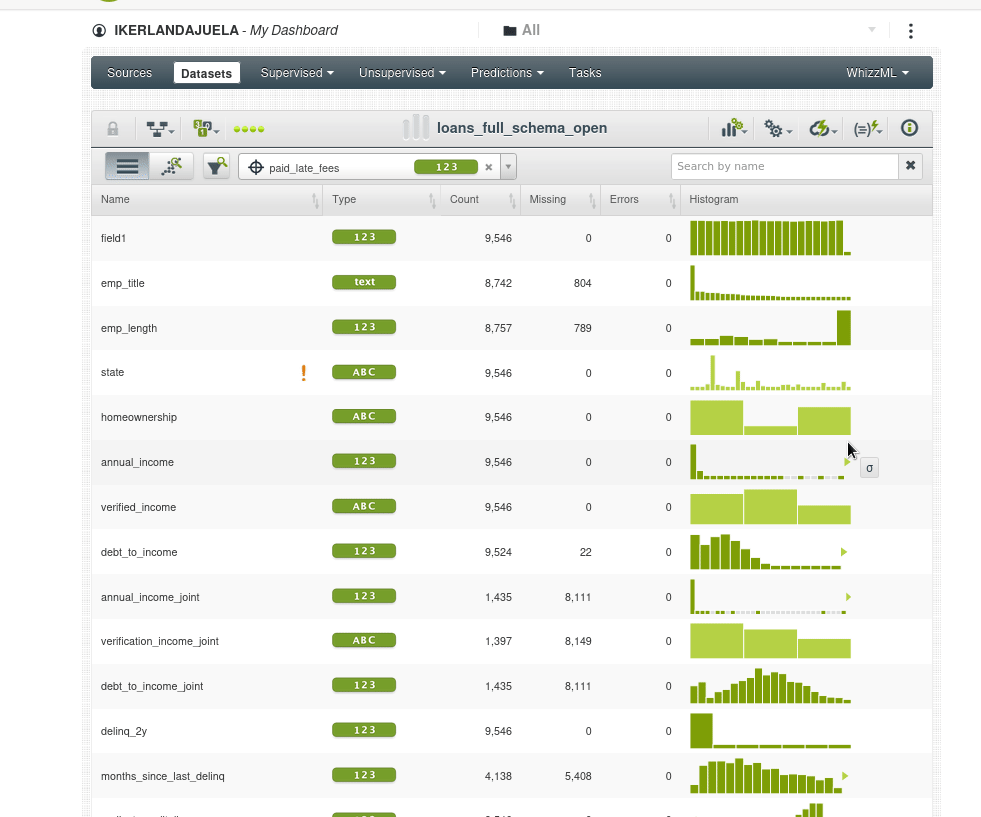
Si vamos al nuevo dataset y observamos el histograma de _loanstatus veremos que solo tenemos los prestamos abiertos:
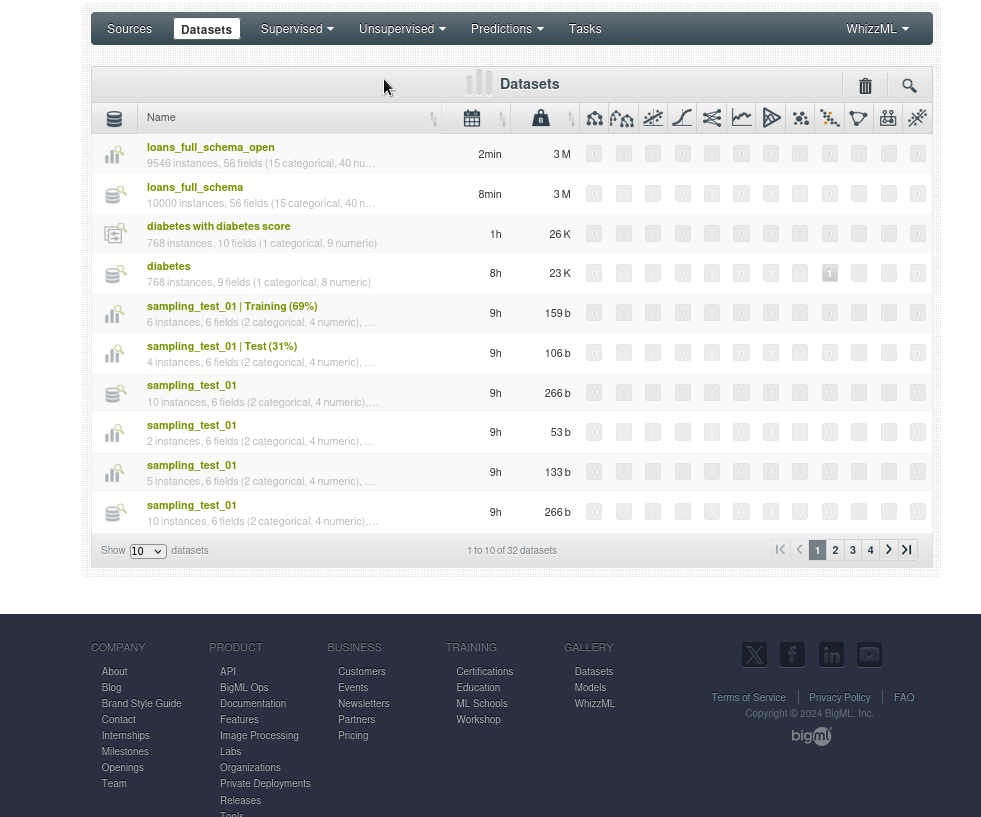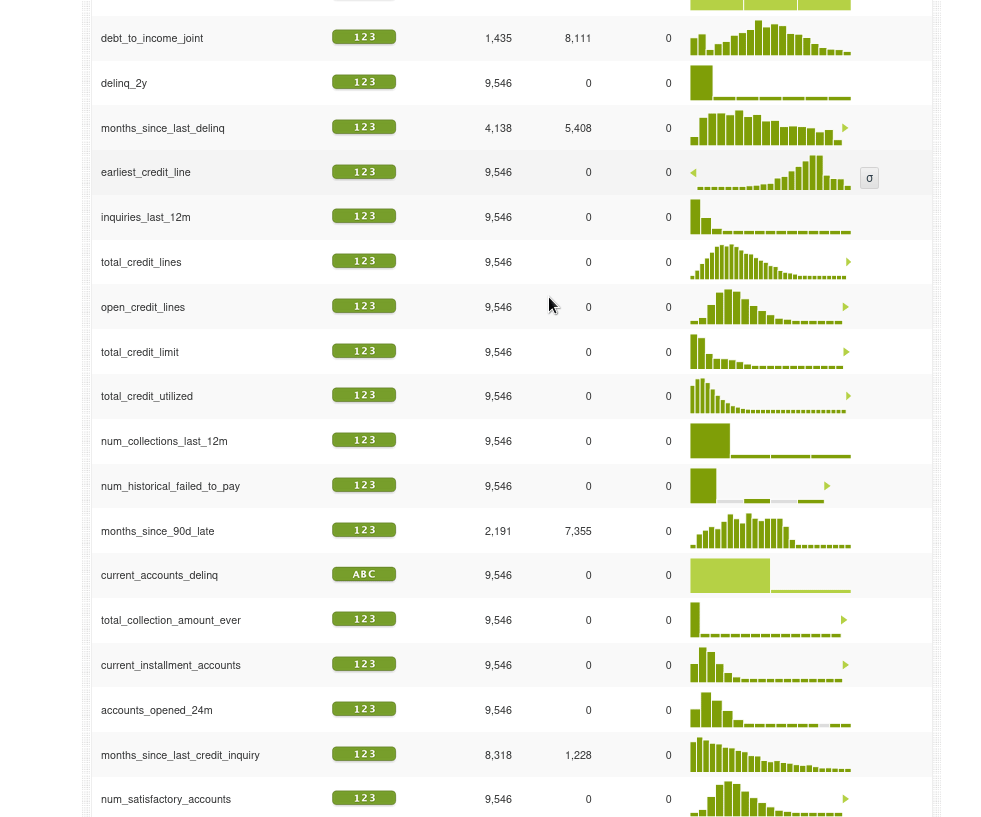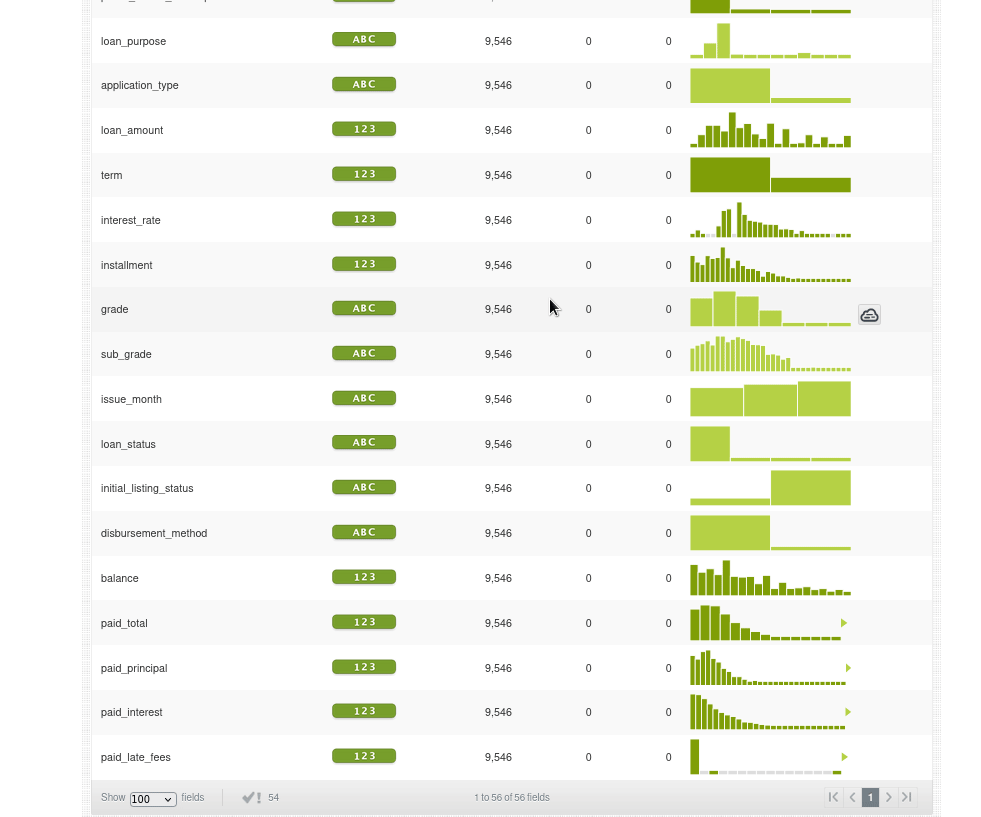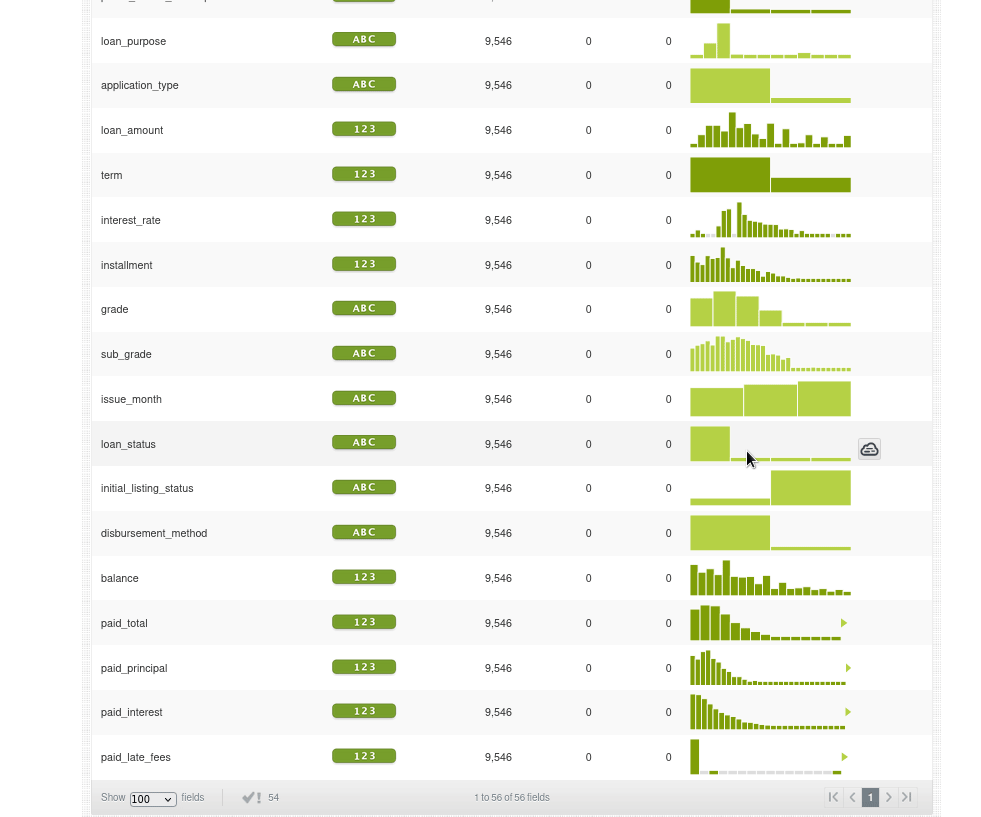
Ahora creamos otro conjunto de datos con los prestamos cerrados:

11.2. Ingeniería de atributos
Ahora realizaremos este paso de ingeniería de atributos.
Dataset: payments.csv
ID,Principal,Interest Rate,Term,Monthly Payment
1,5000,12.00,36,166.07
2,10000,10.00,60,212.47
3,7500,15.00,36,260.81
4,2000,9.50,24,91.43
5,12000,7.00,48,287.31
6,3000,13.50,36,101.48
7,8500,8.00,60,172.33
8,15000,14.00,36,514.12
9,6000,11.00,24,282.66
10,2500,7.50,36,77.74
Objetivo: Vamos a añadir un nuevo campo calculado llamado Total Payment, que representará el pago total que el prestatario realizará durante la vida del préstamo. Este valor se calculará multiplicando el pago mensual (Monthly Payment) por el número total de pagos (Term).
Una vez subido el csv y creado el dataset usamos la opción “ADD FIELDS”
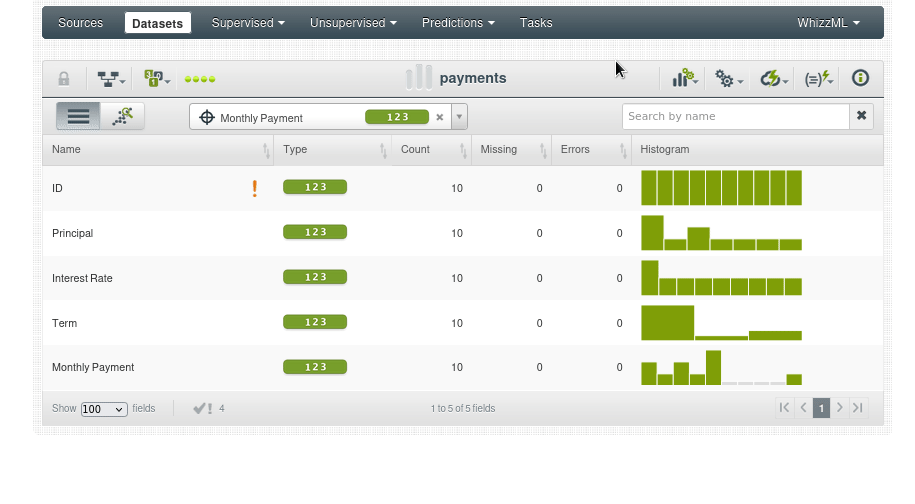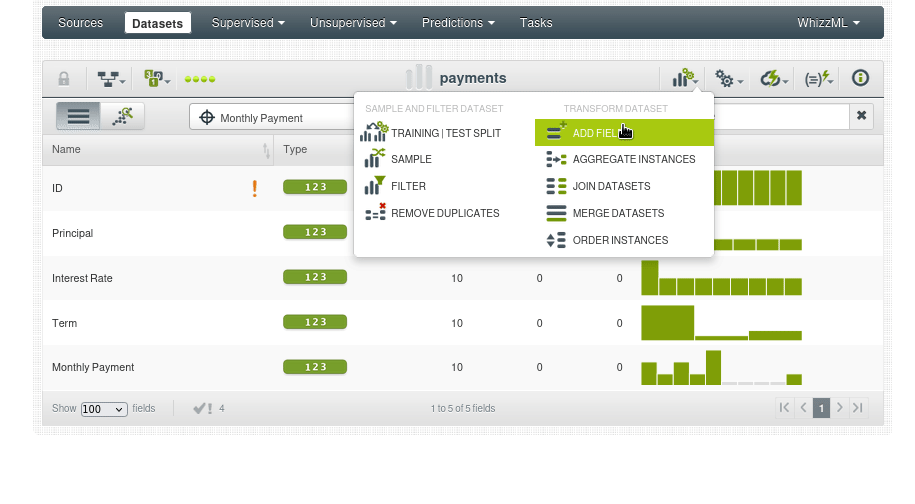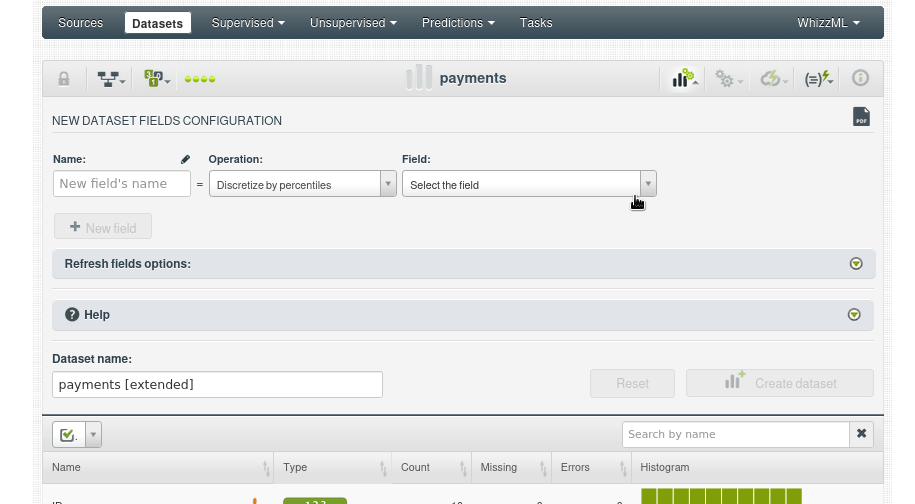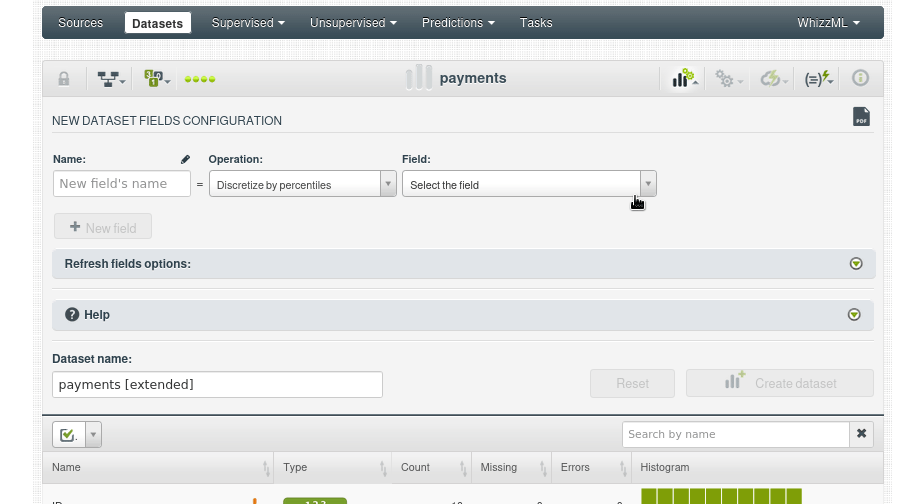
Se abrirá una ventana donde puedes definir el nuevo campo. Aquí, dale el nombre Total Payment al nuevo campo, usaremos una formula en Lisp (Lisp flatline formula):
( * (f "Monthly Payment") (f "Term") )
Dale un nombre al nuevo dataset, por ejemplo payments_total y crea el nuevo conjunto de datos:
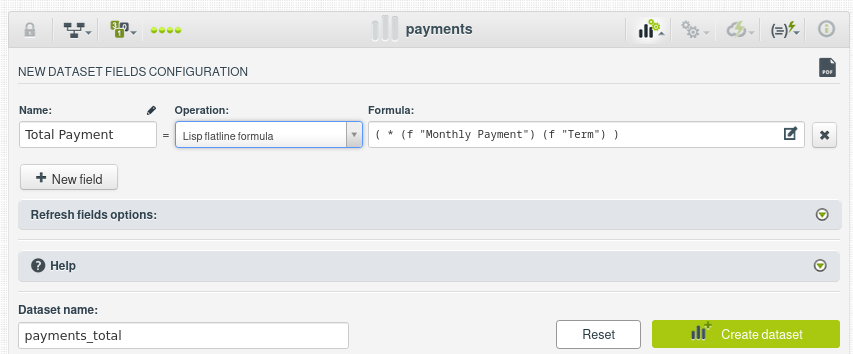
El resultado, el nuevo campo está marcado como una formula:
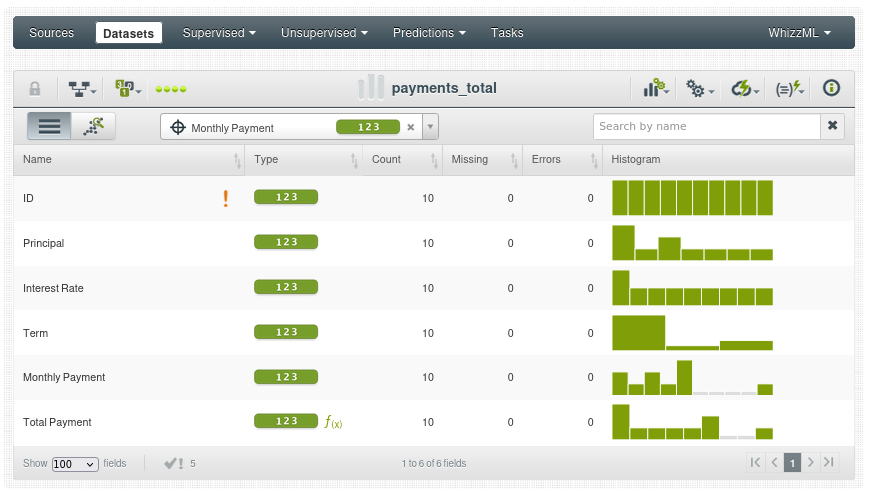
La verdad es que este ejemplo es muy básico, en el documentación oficial Adding Fields to a Dataset profundiza en todas las opciones que ofrece (funciones matemáticas, normalización, percentiles, etc). Recomiendo la lectura del artículo, más adelante si tenemos tiempo le dedicaremos un capítulo entero a como agregar campos nuevos calculados de los ya existentes.