- 1. PREPROCESADO DE DATOS
- 2. Etapas
- 2.1. Limpieza de datos
- 2.2. Transformación de datos
- 2.2.1. Escalado o normalización
- 2.2.2. Codificación de variables categóricas
- 2.2.3. Selección de atributos
- 2.2.4. Discretización
- 2.2.5. Generación de jerarquía de conceptos
- 2.2.6. Agregación de datos
- 2.3. Reducción de datos
- 2.3.1. Reducción de Dimensionalidad
- 3. REFERENCIAS
1. PREPROCESADO DE DATOS
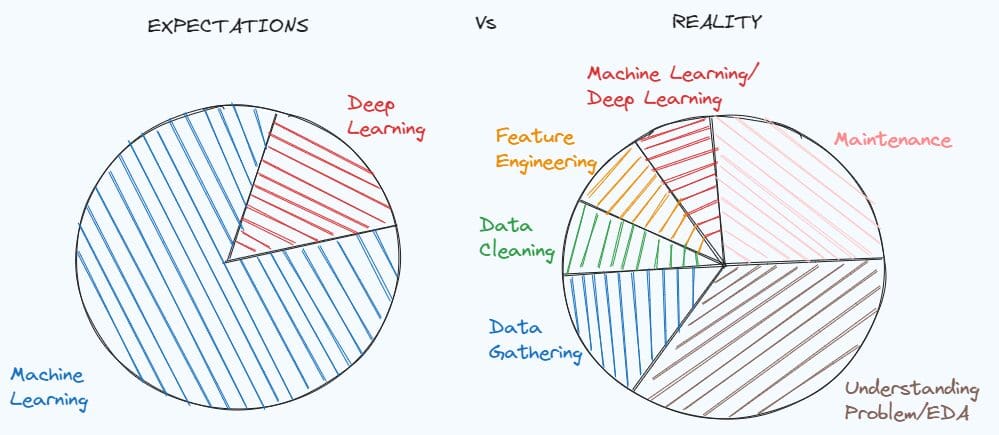
Ésta es la fase a la que dedicaremos el 80% del tiempo total invertido en la resolución de cualquier problema basado en datos.
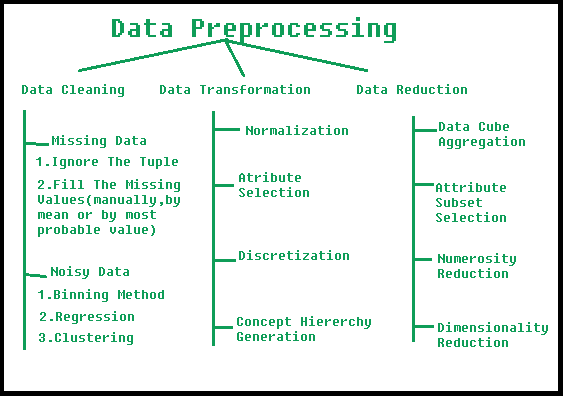
Etapas del preprocesamiento de datos [Fuente]
2. Etapas
2.1. Limpieza de datos
La limpieza de datos es un paso crucial en el análisis de datos, donde se preparan y corrigen los datos crudos para que sean aptos para el análisis. Esto implica identificar y corregir errores o inconsistencias en los datos, tales como valores ausentes, valores atípicos y duplicados.
Los problemas más comunes en un conjunto de datos crudos son:
- Datos faltantes: Celdas vacías o nulas.
- Duplicados: Filas repetidas en el conjunto de datos.
- Valores atípicos (outliers): Valores que se desvían significativamente de los demás.
- Inconsistencias en el formato: Variaciones en mayúsculas y minúsculas, diferentes formatos de fechas.
- Errores tipográficos: Datos mal escritos o mal ingresados.
- Valores irrelevantes: Datos que no aportan valor al análisis o que no son necesarios.
2.1.1. Datos ausentes / faltantes
Esta situación surge cuando faltan valores para una variable en una observación.
2.1.1. Tipos de valores ausentes
Si quieres profundizar sobre los tipos de valores ausentes que existen puedes leer este artículo 3 Types of Missing Values
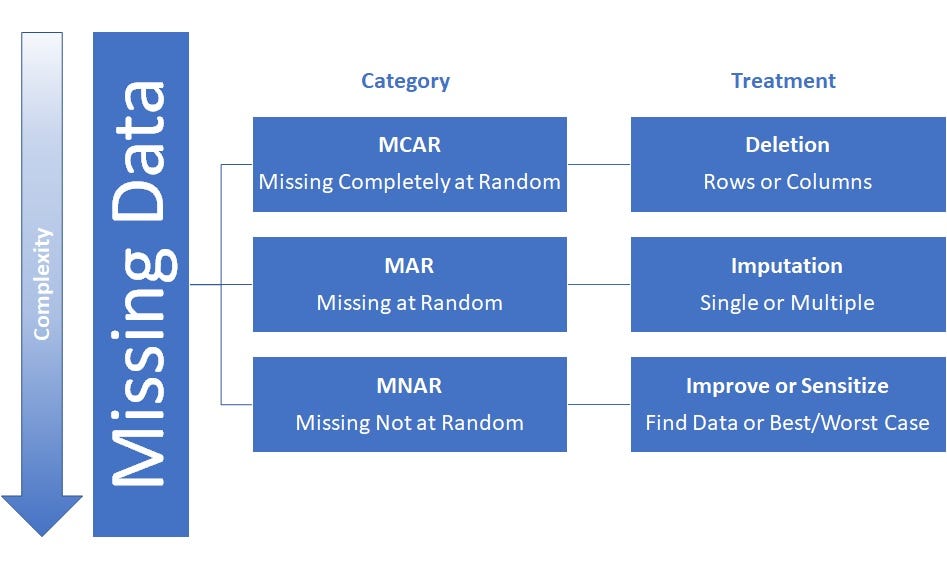
2.1.2. Técnicas para tratar con valores faltantes
Técnicas para tratar con valores faltantes:
Los datos faltantes son comunes y pueden ser tratados de varias formas:
- Eliminar filas o columnas: Si la cantidad de datos faltantes es alta y su presencia no es crítica.
- Imputación de valores: Llenar los valores faltantes con la media, mediana, moda o con valores derivados del propio contexto de los datos.
- Interpolación: Para datos continuos, se pueden interpolar los valores basados en su tendencia.
2.1.2. Diferencia entre Dato Incorrecto y Dato Atípico
Diferencia entre Dato Incorrecto y Dato Atípico (outlier en inglés): en la variable altura del paciente, un dato incorrecto sería 4 metros (es imposible) mientras que un dato atípico sería 2 m. (no es común). Otro ejemplo muy frecuente de dato incorrecto sería tener simultáneamente en la misma variable altura, unos valores expresados en centímetros (162, 202, …) y otros en metros (1,54; 2,05). Los datos incorrectos hay que eliminarlos porque producen errores graves en las conclusiones obtenidas. La forma más sencilla de detectarlos es conocer bien la variable y establecer sus umbrales máximos y mínimos. En el caso de tratar imágenes o series temporales, donde puede existir interferencias por una relación temporal o espacial entre las variables, habrá que aplicar técnicas de procesado de señales/imágenes para reducir o eliminar dicho ruido.
2.1.3. Detección/caracterización de outliers
Como hemos explicado en el primer punto, los datos atípicos (outliers) pueden llevar a error en las conclusiones, haciendo inestable el modelo matemático. En el caso de los modelos lineales (se ajustan a la media de los valores) la existencia de un valor extremo le afectaría muy negativamente (desvirtuaría esa media) y, el modelo, ante datos nuevos, dará un resultado menos exacto. La figura inferior lo explica visualmente: el círculo es el atípico en comparación con el resto de puntos que son “x”. El modelo A, sin outlier, quedaría mucho más ajustado que el modelo B (con) a la media de la mayoría de los valores:
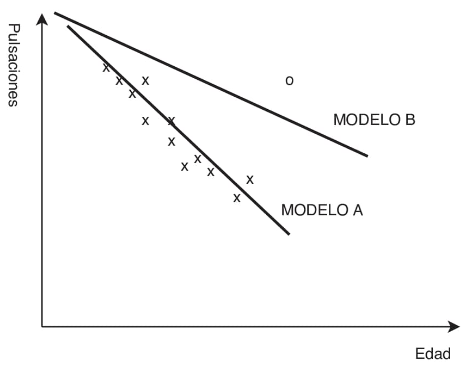
Para detectar si hay outliers en las variables, una aproximación es observar la diferencia entre la media y la mediana de la variable a analizar y, si toma un valor muy diferente a cero, existen outliers. Otro procedimiento clásico es definir un rango [m — 3 * σ, m + 3 * σ] y los outliers son los valores fuera del rango (donde m es el valor medio de la variable y σ es su desviación estándar).
Comparación de medias comunes de valores [ 1, 2, 2, 3, 4, 7, 9 ]
| Tipo | Descripción | Ejemplo | Resultado |
|---|---|---|---|
| Media aritmética | Suma de los valores de un conjunto de datos dividida por el número de valores | (1 + 2 + 2 + 3 + 4 + 7 + 9) / 7 | 4 |
| Mediana | Valor intermedio que separa la mitad de los valores mayores y la mitad de los valores menores de un conjunto de datos. | 1, 2, 2, 3, 4, 7, 9 | 3 |
| Moda | Valor más frecuente en un conjunto de datos | 1, 2, 2, 3, 4, 7, 9 | 2 |
Fuente: Wikipedia Mediana (estadística)
Se pueden tratar de las siguientes maneras:
- Eliminación de las filas con outliers.
- Sustitución de outliers por valores menos extremos.
- Transformación de los datos para reducir la influencia de outliers.
2.2. Transformación de datos
Este paso se da con el fin de transformar los datos en formas adecuadas para el data mining.
La transformación de datos es una etapa en el análisis de datos donde se modifican y ajustan los datos crudos para convertirlos en un formato que facilite su análisis y modelado. Este proceso incluye la aplicación de fórmulas matemáticas, la normalización, la estandarización y la creación de nuevas variables, entre otras operaciones. El objetivo principal es estructurar y mejorar la calidad de los datos para obtener conclusiones más significativas.
2.2.1. Escalado o normalización
Normalización es el proceso de ajustar los valores de las características en un dataset para que estén en una misma escala, generalmente en un rango de 0 a 1.
La diferencia de rangos entre variables puede impactar negativamente el resultado de algunos modelos de aprendizaje máquina. Si tenemos una variable con valores entre 0 y 106 y otra con valores entre 0 y 103, la mayoría de los algoritmos dará más importancia a la primera variable más que a la segunda no por su importancia en el problema a resolver sino por el rango de sus valores, por lo que será necesario normalizar las variables antes de empezar a trabajar.
- Min-Max Scaling: Transforma los datos para que se encuentren dentro del rango [0, 1].
- Estandarización (Z-score): Transforma los datos para que tengan una media de 0 y una desviación estándar de 1.
2.2.2. Codificación de variables categóricas
Para variables categóricas (por ejemplo, colores: rojo, azul, verde), es necesario convertirlas en una representación numérica que los modelos puedan entender:
- One-Hot Encoding: Crea una columna binaria para cada categoría.
- Label Encoding: Asigna un número entero a cada categoría.
2.2.3. Selección de atributos
En esta estrategia, se construyen nuevos atributos a partir del conjunto de atributos dado para ayudar en el proceso de minería (Feature engineering).
2.2.4. Binning o discretización
La discretización es una técnica de preprocesamiento de datos que convierte valores continuos en valores discretos (en intervalos o “bins”), es decir, agrupa los datos en intervalos o categorías específicas. Esto es útil cuando trabajamos con algoritmos de machine learning que funcionan mejor con datos categóricos o cuando queremos simplificar la representación de los datos para facilitar su análisis.
2.2.5. Generación de jerarquía de conceptos
Aquí los atributos se convierten del nivel inferior al nivel superior en la jerarquía. Por ejemplo: el atributo “ciudad” se puede convertir en “país”.
2.2.6. Agregación de datos
Un función de agregación es una función en la que se procesan varios valores juntos para formar una sola estadística resumida. Consiste en combinar datos para obtener un valor resumen, como la media, mediana, suma, o cualquier otra métrica que resuma un conjunto de datos. Es útil cuando se trabaja con datos jerárquicos o series de tiempo.
2.3. Reducción de datos
La reducción de datos es un conjunto de técnicas en data mining que busca simplificar y disminuir la cantidad de datos necesarios para el análisis sin perder información significativa. Esto se logra mediante la eliminación de redundancias y la compactación de la representación de los datos. Estas técnicas son cruciales para mejorar la eficiencia y eficacia de los procesos de análisis y minería de datos.
2.3.1. Reducción de Dimensionalidad
Análisis de Componentes Principales (PCA)
Técnica de reducción de dimensionalidad que transforma los datos a un nuevo espacio de características (componentes principales) que maximiza la varianza. Se utiliza para reducir el número de características manteniendo la mayor parte de la variabilidad de los datos.
Análisis de Componentes Independientes (ICA)
Técnica similar a PCA, pero se centra en identificar componentes independientes en lugar de componentes que maximicen la varianza. Se utiliza cuando se requiere identificar señales independientes en los datos.
3. REFERENCIAS
- https://www.geeksforgeeks.org/data-preprocessing-in-data-mining/
- https://medium.com/@heysan/understanding-and-handling-outliers-in-data-analysis-727a768650fe
- https://medium.com/@nafisaidris413/streamlining-data-preprocessing-and-cleaning-in-a-machine-learning-pipeline-a6e602de2e57
- https://towardsdatascience.com/encoding-categorical-variables-a-deep-dive-into-target-encoding-2862217c2753
- https://medium.com/@tiyasanin1/data-preprocessing-with-python-a-case-study-on-diamond-cd9f944662fc
- https://medium.com/@reinapeh/16-data-feature-normalization-methods-using-python-with-examples-part-1-of-3-26578b2b8ba6
- https://medium.com/@mfahadbashir/understanding-and-handling-outliers-in-data-analysis-97862bd36a8f
- https://learningmilestone.com/why-you-need-to-use-categorical-encoding-for-preprocessing-f58c8798e3ad
- https://medium.com/illumination/data-cleaning-across-multiple-formats-using-python-8ccdd730035e
- https://medium.com/@Mandeep2002/one-hot-encoding-ab823d2dbb11
- https://medium.com/@NextGenTec/dive-into-machine-learning-data-preprocessing-and-preparation-99eff22cc16c
- https://becominghuman.ai/what-does-feature-scaling-mean-when-to-normalize-data-and-when-to-standardize-data-c3de654405ed
- https://medium.com/@rajataha062/mastering-data-preprocessing-in-python-for-machine-learning-af54c68d4b20
- https://pub.towardsai.net/outlier-detection-and-treatment-9a9f41df0fb2