1. TÉCNICAS DE CLASIFICACIÓN
1.1. Árboles de decisiones
Un árbol de decisión es un modelo de machine learning utilizado tanto para tareas de clasificación como de regresión. Se representa como una estructura en forma de árbol, donde cada nodo interno representa una característica (o atributo) de los datos, cada rama representa una regla de decisión, y cada nodo hoja representa un resultado (etiqueta o valor).
1.1.1. Ejemplo: Decisión de Compra de un Coche
Para ilustrar cómo funciona un árbol de decisión, consideremos un ejemplo sencillo de clasificación. Supongamos que queremos predecir si una persona comprará o no un coche basado en tres características: edad, ingreso y estado civil.
Paso 1: Recolección de Datos
Tenemos el siguiente conjunto de datos de entrenamiento:
| Edad | Ingreso | Compra |
|---|---|---|
| <=30 | Alto | No |
| <=30 | Alto | No |
| 31-40 | Medio | Sí |
| >40 | Alto | Sí |
| >40 | Medio | Sí |
| 31-40 | Bajo | Sí |
| <=30 | Medio | No |
| >40 | Alto | No |
| <=30 | Medio | Sí |
| 31-40 | Alto | Sí |
Paso 2: Construcción del Árbol de Decisión
El algoritmo de construcción de un árbol de decisión selecciona la característica que mejor separa los datos en cada paso.
Para simplificar, supondremos que nuestro algoritmo ha seleccionado “Edad” como la característica de raíz que mejor separa nuestros datos:
Edad
/ | \
<=30 31-40 >40
/ | | \
Alto Medio Bajo Alto
/ \ | | / \
No No Sí Sí Sí No
Paso 3: Interpretación del Árbol
El árbol de decisión anterior se puede interpretar de la siguiente manera:
- Si la edad es menor o igual a 30 y el ingreso es Alto, la persona no comprará el coche.
- Si la edad es menor o igual a 30 y el ingreso es Medio, la persona comprará el coche.
- Si la edad es entre 31 y 40 y el ingreso es Medio o Bajo, la persona comprará el coche.
- Si la edad es mayor a 40 y el ingreso es Alto, la persona comprará el coche si está casado y no lo comprará si es soltero.
Paso 4: Uso del Árbol de Decisión
Para predecir si una nueva persona comprará un coche, simplemente seguimos las ramas del árbol según las características de esta persona. Por ejemplo, para una persona de 28 años, con ingreso Medio y estado civil Soltero:
- Edad: <=30 (nos movemos a la rama izquierda)
- Ingreso: Medio (seguimos la sub-rama “Medio”)
De acuerdo al árbol, esta persona comprará el coche.
1.2. Reglas de asociación
Las reglas de asociación se utilizan para descubrir hechos que ocurren en común dentro de un determinado conjunto de datos. Se han investigado ampliamente diversos métodos para aprendizaje de reglas de asociación que han resultado ser muy interesantes para descubrir relaciones entre variables en grandes conjuntos de datos.
1.2.1. Ejemplo: Cesta de la compra
Imaginemos un pequeño conjunto de datos de transacciones en una tienda:
| Transacción | Artículos |
|---|---|
| 1 | Pan, Mantequilla |
| 2 | Pan, Leche |
| 3 | Pan, Mantequilla, Leche |
| 4 | Leche, Mantequilla |
| 5 | Pan, Leche, Mantequilla, Jugo |
Paso 1: Generación de Conjuntos Frecuentes
El primer es identificar los conjuntos de artículos que aparecen juntos con frecuencia. Utilizaremos el soporte (support) para medir la frecuencia de los conjuntos de artículos.
Soporte: La proporción de transacciones que contienen un conjunto específico de artículos.
Por ejemplo, el soporte para el conjunto {Pan, Mantequilla} es:

Paso 2: Generación de Reglas de Asociación
Una vez que tenemos los conjuntos frecuentes, podemos generar reglas de asociación. Estas reglas tienen la forma A => B, donde A y B son conjuntos de artículos.
Confianza: La proporción de transacciones que contienen A y también contienen B.
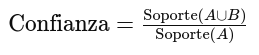
Ejemplo de Regla de Asociación:
Consideremos la regla Pan => Mantequilla.
Soporte de {Pan, Mantequilla}: Ya calculamos que es 0.6.
Soporte de {Pan}:

Confianza de Pan => Mantequilla:
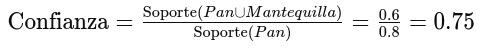
Esto significa que el 75% de las veces que se compra Pan, también se compra Mantequilla.
Interpretación de las Reglas de Asociación
Las reglas de asociación nos ayudan a identificar relaciones entre productos. En nuestro ejemplo, la regla Pan => Mantequilla con una confianza del 75% sugiere que los clientes que compran pan también tienden a comprar mantequilla. Esta información puede ser útil para diversas aplicaciones como marketing y ventas o la gestión del inventario.
Resumen de las Métricas
- Soporte: Indica la popularidad de un conjunto de artículos.
- Confianza: Indica la fiabilidad de la regla
A => B.
Ejemplo Completo de Reglas de Asociación
Vamos a derivar algunas reglas adicionales usando los datos anteriores:
Regla:
Leche => Mantequilla- Soporte de
{Leche, Mantequilla}: 0.6 (Aparece en 3 de 5 transacciones) - Soporte de
{Leche}: 0.8 (Aparece en 4 de 5 transacciones) - Confianza: 0.6 / 0.8 = 0.75
- Soporte de
Regla:
Mantequilla => Pan- Soporte de
{Pan, Mantequilla}: 0.6 - Soporte de
{Mantequilla}: 0.8 (Aparece en 4 de 5 transacciones) - Confianza: 0.6 / 0.8 = 0.75
- Soporte de
Regla:
Pan, Leche=>Mantequilla- Soporte de
{Pan, Leche, Mantequilla}: 0.4 (Aparece en 2 de 5 transacciones) - Soporte de
{Pan, Leche}: 0.4 (Aparece en 2 de 5 transacciones) - Confianza: 0.4 / 0.4 = 1.0
- Soporte de
La última regla Pan, Leche => Mantequilla tiene una confianza del 100%, lo que significa que cada vez que se compran pan y leche juntos, también se compra mantequilla.
1.3. Algoritmos genéticos
Los algoritmos genéticos son procesos de búsqueda heurística que simulan la selección natural. Usan métodos tales como la mutación y el cruzamiento para generar nuevas clases que puedan ofrecer una buena solución a un problema dado.
1.4. Redes neuronales artificiales
Las redes de neuronas artificiales (RNA) son un paradigma de aprendizaje automático inspirado en las neuronas de los sistemas nerviosos de los animales. Se trata de un sistema de enlaces de neuronas que colaboran entre sí para producir un estímulo de salida. Las conexiones tienen pesos numéricos que se adaptan según la experiencia. De esta manera, las redes neurales se adaptan a un impulso y son capaces de aprender. La importancia de las redes neurales cayó durante un tiempo con el desarrollo de los vectores de soporte y clasificadores lineales, pero volvió a surgir a finales de la década de 2000 con la llegada del aprendizaje profundo.
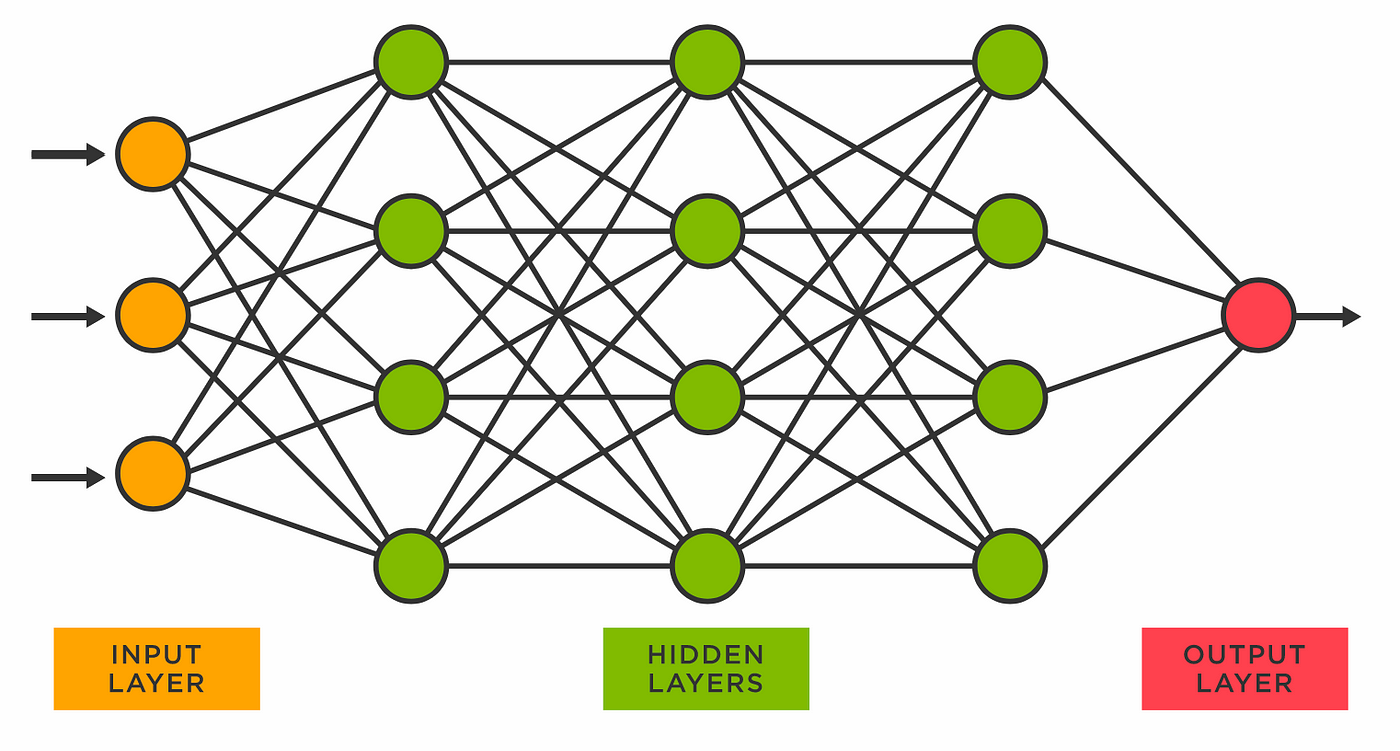
1.5. Máquinas de vectores de soporte
Las MVS son una serie de métodos de aprendizaje supervisado usados para clasificación y regresión. Los algoritmos de MVS usan un conjunto de ejemplos de formación clasificada en dos categorías para construir un modelo que prediga si un nuevo ejemplo pertenece a una u otra de dichas categorías.
1.6. Algoritmos de agrupamiento
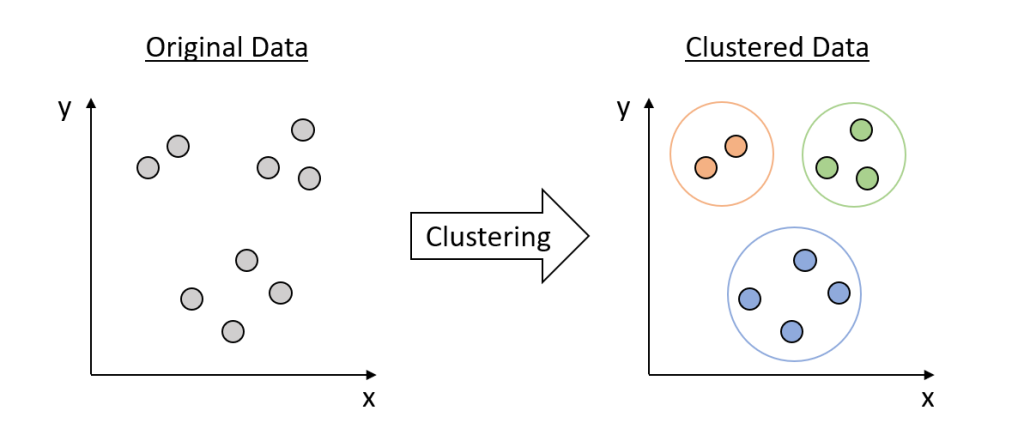
El análisis por agrupamiento (clustering en inglés) es la clasificación de observaciones en subgrupos —clusters— para que las observaciones en cada grupo se asemejen entre sí según ciertos criterios.
Las técnicas de agrupamiento hacen inferencias diferentes sobre la estructura de los datos; se guían usualmente por una medida de similitud específica y por un nivel de compactamiento interno (similitud entre los miembros de un grupo) y la separación entre los diferentes grupos.
El agrupamiento es un método de aprendizaje no supervisado y es una técnica muy popular de análisis estadístico de datos.
1.7. Redes bayesianas
Una red bayesiana es una representación gráfica de probabilidades condicionadas entre un conjunto de variables. Esta representación permite entender y modelar la incertidumbre y las dependencias entre diferentes variables en un sistema.

Una red Bayesiana simple. Influencia de la lluvia si el rociador está activado e influencia de la lluvia y el rociador si la hierba se encuentra húmeda.